Shishir Agrawal, agrawal@cse.wustl.edu
The last couple of years have seen several major changes in the internetwork traffic pattern. First, there has been an explosive growth of Internet in terms of its size and volume. Second, there has been an increase in number of multimedia and real-time applications in the network. These changes have put significant pressure on the network to support higher bandwidth and provide quality of service guarantees. Till now IP has fared well in terms of scalability because of its connectionless nature. However the hop-by-hop packet forwarding paradigm of IP is turning out to be insufficient in supporting the newer networking demands and the routers are becoming a bottleneck. As such, there is need for improvement in router/routing technology in terms of packet forwarding performance, adapting to newer routing functionalities and providing sufficient network guarantees to support desired quality of service. Another major change has been the introduction of ATM (Asynchronous Transfer Mode) technology. Because of its fast label switching capabilities, it is being viewed by the industry and academia as a promising technology for faster networking. However, most of the current applications are based on IP and hence the success of ATM depends a lot on its capabilities to support IP and other higher layer protocols.
To counter one or more of above problems, several independent approaches have been made which can be divided into two broad categories. One is to run IP over ATM and other is to use the label switching technology of ATM for packet forwarding. This paper does a survey of these approaches.
The paper is organized as follows. Section 2 discusses initial approaches of IP over ATM, section 3 discusses Ipsilon's IP switching, section 4 discusses Cisco's Tag Switching, Section 5 discusses IBM's ARIS, section 6 discusses MPLS proposed by IETF and section 7 summarizes the paper. This is followed a list of references.
This section gives a very brief overview of the efforts made by ATM Forum and IETF for running IP over ATM.
This architecture has been proposed by ATM Forum and can be considered as one of the earliest efforts for running IP over ATM. The idea is to make an ATM LAN appear as a set of logical shared medium LANs interconnected via routers. A shared LAN is emulated by setting up an ATM multicast group between all of the nodes that belong to the same logical LAN. For data transfer between nodes, an address resolution server is used to translate MAC address to an ATM address and then a point-to-point virtual channel is established between the nodes. Main disadvantages of this solution are the use of routers for transferring data within same physical ATM LAN and servers being single point of failures.
This architecture has been proposed IETF's IPOA WG. Here a group of ATM stations are divided into Logical IP Subnets ( LIS ), interconnected via routers. Each LIS has an ATMARP server for resolution between IP address and ATM address. There is no broadcast service within a LIS. In this architecture also nodes in different LIS have to communicate via routers even if they are directly connected.
This protocol has been proposed by IETF's Routing Over Large Clouds ( ROLC ) WG to counter the problem of going through the routers between logical subnets. The goal here is to locate an exit point in the ATM cloud closest to the destination and to obtain its ATM address. Here we have NHRP servers which provide the next hop towards the destination. These NHRP servers interact with each other to get resolve the exit point closest to the destination.
This has been proposed by ATM Forum. It is an extension of LANE. MPOA uses NHRP to resolve the ATM address of an exit point closest to destination and provide direct layer 3 connectivity across an ATM fabric. MPOA operates at both layer 2 and layer 3. It also includes protocols to replicate servers and distribute the database for reasons of capacity and availability.
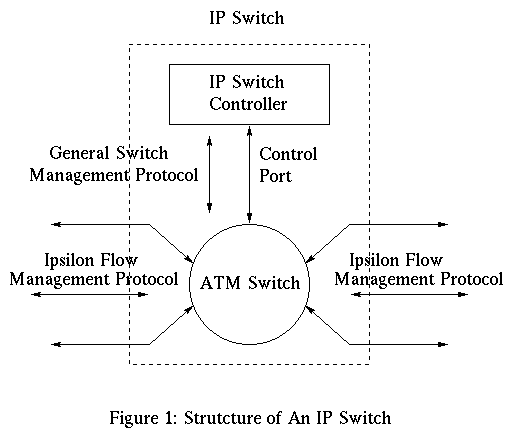
This technology [4,Flow Labeled IP] has been developed by Ipsilon Networks Inc. The goal of Ipsilon is to make IP faster and offer the quality of service support. The "IP over ATM" approach tries to hide the underlying network topology from IP layer by treating the datatlink layer as large, opaque network cloud. However, this leads to inefficiency, complexity and duplication of functionality in the resulting network[5,ATM under IP]. Ipsilon's approach is to discard the connection-oriented ATM software and implement the connectionless IP routing directly on the top of ATM hardware. This approach takes the advantage of robustness and scalability of connectionless IP and speed, capacity and scalability of ATM switches.
IP switch ( refer 2 Figure 1, taken from [5, ATM under IP] ) is basically an IP router with attached switching hardware that has the ability to cache routing decisions in switching hardware. To construct an IP switch, a standard ATM switch is taken, the hardware is left untouched, but all the control software above AAL-5 is removed. It is replaced by standard IP routing software, a flow classifier to decide whether to switch a flow or not and a driver to control the switch hardware. At system startup a default virtual channel is established between the control software of the IP switch and its neighbors, which is then used for default hop-by-hop forwarding of IP datagrams. To gain the benefits of switching, a mechanism has been defined to associate IP flows with the ATM labels.
A flow is a sequence of packets from a source to a destination which get the same forwarding treatment at a router. An IP flow is characterized by the fields in IP/TCP/UDP header such as source address, destination address, port number, etc. Currently two types of flows have been defined by Ipsilon. Host pair flow type is defined for traffic between same source and destination IP address. A Port pair flow type is defined for traffic between same source and destination port between same source and destination IP address.
When a packet is assembled and submitted to controller in IP switch, apart from forwarding it to the next hop it also does flow classification. Flow classification decision is a policy decision local to a IP switch. Depending on the classification, the switch decides to forward or switch the next packets of that flow. Usually the controller would decide to forward short term flows like database queries, DNS messages and switch long term flows like ftp or telnet data.
When an IP switch controller decides to switch a flow, it performs the following steps to establish a flow. Please refer to Figure 2 ( taken from [5, ATM under IP]).
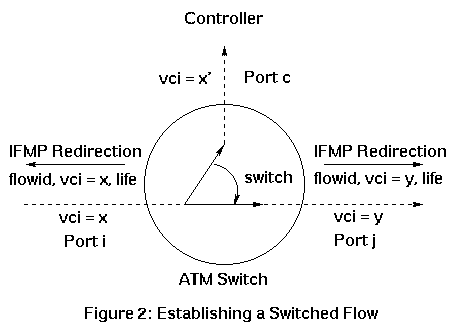
Each IP switch maintains a refresh timer. When the timer goes off, the state of each flow is examined and either a flow is refreshed by resending the IFMP Request message or the label is reclaimed for reuse by sending an IFMP Reclaim message upstream. Also, when an IP switch redirects packets on a specific virtual channel, it removes all the header fields that characterize the flow from the header of each packet. The removed fields are stored by the router that issues the redirection message. This allows IP switch to act as a security firewall without having to inspect the contents of each packet.
Following are some important features of IP Switching :
According to the simulations performed by Ipsilon[7, Iterop96], 80 - 90 percent of data in the Internet traffic is suitable for switching. The number of connection setups per second is also well within the capabilities of ATM.
This technology has been developed by Cisco Systems Inc. to enhance routing in terms of bandwidth, scalability, support to newer routing functionalities, multicast, hierarchy of routing knowledge and flexible routing control. It uses the label ( called tag here ) switching technology for layer 3 packet forwarding. The tag switching technology consists of forwarding and control components[8, RFC 2105] which are described below:
The forwarding component uses the tags carried by the packets and the tag forwarding information stored in the switch to perform packet forwarding. It consists of following:
Packets in tag switching environment can carry tags in one of the following ways:
Routers/Switches which support tag switching are called tag-switches. A tag-switch carries tag forwarding information in a database called Tag Information Base (TIB). Each entry in the TIB is in the form of an incoming tag with one or more subentries of the form (outgoing tag , outgoing interface, outgoing link level information)
When a tag-switch receives a packet with tag, it uses the tag as an index to lookup information in TIB. On finding an entry with incoming tag equal to the tag of the packet, for every subentry of the entry, the switch replaces the tag and the link level information in the packet by the outgoing tag and link information in the subentry and sends the packet to the outgoing interface.
Since the forwarding procedure involves fixed length matching of tag entries, it can be implemented in hardware and thereby increasing the packet forwarding performance. Secondly, the forwarding procedure is independent of routing functionality ( unicast/multicast, routing protocol used, etc). As such the forwarding component is independent of the Network Layer.
In a tag switching there is a binding between a tag and network layer routing. A tag could be bound to an individual application flow, a single route, group of routes or a multicast tree. The primary function of control component is to create tag bindings and distribute the tag binding information among the interconnected tag-switches. The control component consists of a set of modules, one handling each routing function, thus supporting scalability of routers in terms of routing functionalities. Some of the routing functions which tag switching supports are described below.
Tag Switching supports destination based routing in the following manner. A tag switch, like a router, would participate in network layer routing protocols and construct its Forwarding Information Base (FIB) using the information obtained from these protocols. Then it would use one of the following 3 methods for tag allocation, creation of TIB and distribution of tag bindings.
Once the tag allocation is done and binding created, the switch which allocated the tags, distributes it to the other interconnected tag switches by either piggybacking the binding on existing routing protocols or using a separate Tag Distribution Protocol[9, TDP] . When a previously untagged packet enters a network of tag switches, a tag is added to its header by the first tag switch in its route, then the packet is switched through the network and the tag is removed by the last tag switch in its route. Since the existence of entry in FIB causes tag allocation, hence tag switching is topology driven.
IP routing views network as a set of routing domains. Though it separates intra-domain routing from inter-domain routing, all the routers in a domain which route transit traffic, maintain same amount of information which degrades network performance and increases routing convergence time. To recognize the domain boundaries, tag switching allows a packet to carry a set of tags arranged in the stack form. Thus, in the IP environment a packet will have 2 tags, for inter-domain and intra-domain switching. This helps to improve overall network performance and decrease routing convergence time.
To support multicast forwarding function, tag switching associates a tag with multicast tree. When a tag-switch creates a multicast forwarding entry in its TIB, it creates a local outgoing tag and a subentry for each outgoing interface.
Destination based routing do not support routing on basis of any parameter other than the destination address. This limits the capacity of network to do load balancing. Tag switching overcomes this shortcoming by allowing binding of tags to specific routes, which can be different from the routes decided by the destination address.
To support QoS selection a router should be able to classify packets as belonging to a particular class and forward them such that the QoS selection is satisfied. Tag switching helps QoS by assigning a tag to a class of packets once the classification has been done. This eliminates the need to reclassify packet at each router.
Cell Switched Router ( CSR ) technology has been introduced by Toshiba Corporation, Japan. "IP over ATM" approach discussed in section 1 doesn't take into account operation with newer IP protocols like RSVP. On the other hand, just the use of resource reservations and flows in IP has basic throughput limitations as compared to the cell switching mechanism of ATM. Toshiba has proposed CSR based Internetworking Architecture, which tries to merge the two approaches by extending the current routers to handle resource reservation and IP flows using ATM's cell switching capabilities.
Cell switched router is a router which has cell switching functionality of ATM in addition to conventional IP datagram forwarding capabilities. As such, for datagrams which cross IP subnet boundaries, both options of IP header based routing or VPI/VCI based cell switching are available. A CSR can bypass datagram assembly/disassembly by concatenating the incoming and outgoing ATM VCs. By doing such bypass at consecutive CSRs, ATM level connectivity (called "ATM Bypass-pipe") can be provided. There are 2 different kinds of VCs defined between adjacent CSRs or CSR and end host/router.
It is important to note that there can't be any non-CSRs in a Bypass pipe. The route for datagram forwarding is decided on the basis of a routing table entry at each CSR. The same route is also used for creating the Bypass pipe. The route for VCs between two adjacent CSRs is determined using ATM routing protocols like PNNI. The ingress router/host does the job of flow classification. It sees the header fields of each datagram (src address, destination address, port number, etc.) and decides whether the datagram should be sent on default or dedicated VC. The intermediate CSR look at the VPI/VCI of the incoming cells. If there is an entry in the ATM routing table for the VPI/VCI of the incoming cells then they are cell switched, if not then they are assembled and forwarding is done on the basis of entry in IP routing table.
The main functionality of CSR is similar to that of NHRP based IP over ATM architecture, however following are some of the features that bring out the differences between the two.
The flow classification is done by the end hosts/routers and depending of the flow they trigger Bypass pipe setup procedures. If the flow is a short lived flow, then the datagrams are forwarded on the default VCs. If the flows are long-term flows (like FTP, NNTP, etc) which don't require any bandwidth or QoS guarantees, then the end-hosts/routers may decide to forward datagrams on dedicated VCs. In this kind of flow the Bypass pipe setup procedure is sender initiated. If the flows are such that they demand some bandwidth or QoS selection (eg, RSVP), then again the datagrams are forwarded on the dedicated VCs. However the Bypass pipe setup is receiver initiated in this case. Depending on the requirements of the flow, the CSRs can use corresponding service class (ABR/UBR/CBR/VBR) provided by the ATM.
This concept has been introduced by IBM. The goal of ARIS[15, Internet Draft] is to improve aggregate throughput of IP and other network layer protocols by switching datagrams at the media speed.
An Integrated Switched Router (ISR), is a switch augmented with the standard network layer routing support. A switched path is a path in the network along which datagrams can be "switched" at media speed. In a network which uses destination based hop-by-hop datagram forwarding, ARIS uses ISRs instead of switches/routers and pre-establishes switched paths to well known egress nodes. These nodes are recognized from the information provided by routing protocols like OSPF and BGF. The switched paths are established by the ISRs by exchanging ARIS messages described later. They are in the form of tree routed at the egress points. On receiving a datagram, the ingress ISR performs a conventional longest prefix match lookup in its forwarding information base to get the associated switched path label for the destination and then transmits the datagram on that switched path. If no entry is found in the FIB then the datagram is forwarded to the next hop using the default hop-by-hop forwarding path.
ARIS is protocol independent. In case of IP, ARIS messages are transmitted with IP protocol number 104. Following messages are used by ARIS to setup and manage the switched paths.
Egress identifiers define a routed path through the network. They are classified into different types according to the routing protocol information. The various types of egress identifiers in ARIS are:
An ISR maintains following three information bases for management of switched paths and routing datagrams.
This is same as RIB in a standard router. In an ISR, apart from computing best-effort routes, RIB is also used to identify egress points and egress identifiers used in other two information bases.
This contains entries of the form destination prefix, outgoing interface, next hop IP address, egress identifier and the label for the associated switched path. An ISR looks into its FIB for packet forwarding. While the association between next hop IP address and egress identifier is created by IP routing protocol, the association between egress identifier and switched path label is created by ARIS protocol.
This information base maintains the mapping between egress identifiers and upstream/ downstream labels. This mapping is created using ARIS protocol.
Following are some of the important features of ARIS.
Multi-Protocol Label Switching (MPLS )
As discussed in previous sections, several approaches were made in last couple of years to apply layer 2 switching technology (based on label swapping) to layer 3 routing. This led IETF to form MPLS group. The goal of this group is to develop a standard[18, Internet Draft] for integration of layer 2 switching with layer 3 routing in order to improve price/ performance of network layer routing, scalability of network layer and provide greater flexibility in providing new routing services. Though MPLS focuses on IP, it is extendible to other network layer protocols and no assumption is made about layer 2 protocols, except that they are capable of forwarding network layer packets.
A few definitions that would be used extensively in this section are given below. They have been taken directly from the Internet Draft [18, Internet Draft]:
There a set of core components defined by MPLS which can be applied in various ways to achieve the objectives of MPLS.
The approach taken by MPLS is to use standard layer 3 routing protocols like OSPF and BGP without any change. The information maintained by these protocols can be used for generation and distribution of labels. There should be a single routing protocol for routers and switches. Also, the MPLS-capable and MPLS-ignorant routers should be able to co-exist in the same routing domain.
Labels facilitate packet forwarding. The key issues involved with labels are:
MPLS applications should be clear about the semantics they associate with labels. At the simplest level, labels can be a short fixed length representation of packet header, used for indexing the forwarding decision at the routers. However, its possible to associate more semantics with the labels. For example, a label can represent a loop free path or can be the identity of a higher layer protocol type. In any case, labels always have local significance.
The essential point about labels is that all the packets with the same label will receive same forwarding treatment ( ie, forwarded on the same port, with same next hop label (if any) and using same encapsulation ). The granularity of element associated with labels can vary widely. On one hand a label can represent IP flows, explicit routes or host routes. On the other hand, it could represent an egress identifier or egress router (in case of IP unicast ) and a multicast tree ( in case of IP multicast ).
The key point in label switching is the binding between a label and network layer routing. Label assignment involves allocating a label, binding it to routing and distributing it to MPLS switches. Label assignment can be control-traffic driven or data-traffic driven. Though control-traffic driven label assignment has many advantages, data-traffic driven label assignment cannot be done away with. In both cases, label withdrawal is an essential associated functionality which should be taken care of.
The basic forwarding operation involves label swapping as follows. When a packet is received by a label switch, its label is used for index lookup in LIB and information like encapsulation, outgoing interface and outgoing label is retrieved. When a packet first enters an MPLS domain, a label is inserted along-with normal packet forwarding, the process being called "Label Push". When a packet leaves an MPLS domain, the label is removed from the packet, the process being called "Label Pop". In general, a packet can carry a stack of labels, with the label on the top of stack being relevant at any instance.
Label swapping uses several pieces of information like label, TTL field, etc. This information can be encoded in a layer 2 header, then called "MPLS Encapsulation" or an explicit "MPLS Header" could be added to packets. The size, contents and format of MPLS Encapsulation/ Header are still being discussed.
Several observations, issues and assumptions are being discussed by the MPLS group.
This section mentions some of the technical approaches for MPLS framework. For details please refer to [18, Internet Draft].
Rapid growth in size of Internet, increase in number of real-time and multimedia applications, and some other changes in network traffic pattern have motivated several companies and organizations like ATM Forum and IETF to use label swapping technology for network layer forwarding. In this paper we studied different approaches to achieve the same.
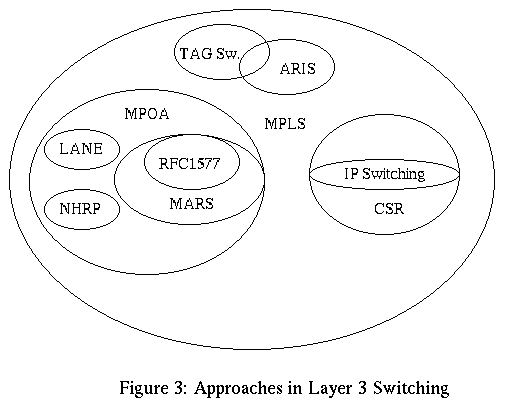
Section 2 presented a brief overview of approaches made by IETF and ATM Forum for running IP over ATM. In section 3 we discussed "IP Switching" technology proposed by Ipsilon. Here ATM switches are modified to do flow classification and switch IP flows at layer 2. In section 4 we discussed "Tag Switching" proposed by Cisco Systems. Here a small tag is carried in the packet header ( implicitly or explicitly ) and the tag is used to switch packets at the routers. In section 5 we studied "CSR based Internetworking Architecture" proposed by Toshiba Corporation, Japan. Here ATM Bypass pipes are used to switch IP packets at layer 2. In section 6 we studied " Aggregate Route based IP Switching" proposed by IBM. This approach establishes a set of switched paths in the network and uses binding of labels to the switched paths for switching packets. Finally, in section 7 we studied "Multiprotocol Label Switching" that is being developed by MPLS WG of IETF. This aims a providing a set of "core" MPLS mechanisms for standardising integrating of layer 2 switching with layer 3 routing. All these approaches can be seen together in a venn diagram (taken from [ 20, Raj Jain]) as shown below:
Last Modified August 16, 1997