| Dolvara Gunatilaka, dgunatilaka@wustl.edu (A paper written under the guidance of Prof. Raj Jain) | Download |
Information-Centric Networking (ICN) proposes a future Internet architecture that revolves about the contents being exchanged rather than the communication of hosts and network devices. This paradigm shift is caused by the tremendous growth of information on the Internet and the increased demands for data access. Many research projects have proposed different ICN approaches over the past few years. Therefore, in this paper, we will give an overview of the ICN concept, and will provide a detailed summary of the recent proposed ICN architectures, which include Network of Information (NetInf), Named Data Networking (NDN), Publish-Subscribe Architecture, COMET, and CONVERGENCE.
Information-Centric Networking, ICN, Content-Centric Networking, Data-Oriented Networking, Future Internet Architecture, Named Data Networking, NDN, Network of Information, NetInf, SAIL, Publish- Subscribe Architecture, PURSUIT, COMET, CONVERGENCE.
The current Internet architecture was designed to center around communication between hosts in the networks. As a result, a user has to specify a host in order to retrieve information. Today, there is a drastic increase in information distribution over the Internet, and the growth demand of information from users. Internet traffic becomes more variable, ranging from multimedia traffic, web pages, real-time streaming, etc. Consequently, the existing Internet architecture could not adapt well to the changes.
The current solution such as TCP/IP becomes inefficient and subjects to certain problems [Haque13]. For example, to search for a specific content, the piece of information must be mapped to a host, and then the DNS translates the host name to the location i.e. IP address. The two-step mapping incurs access overhead. IP address also binds to a location so it does not support node and content mobility. Security is another important issue since the security mechanism is tightly coupled to the host. Therefore, host becomes a target of many security threats. In addition, because the IP router is stateless and does not provide a caching capability, the same request would be made multiple times through the path, and cause an unnecessary bandwidth usage. This prompted the research into shifting Internet architecture from a host-centric to information-centric.
Earlier architectures such as Content Delivery Networks (CDN) and Peer-to-Peer (P2P) addressed similar problems and took the initiative to improve user's information access. Then, Information Centric Networking (ICN) has been subsequently proposed for the future Internet architecture. The main concept of ICN is to deploy content name at the network level. The content identifier is independent of its location, therefore allowing content to move freely on the Internet. ICN supports in-network caching, which helps the content to become closer to the user. Security is coupled with the content rather than the host. Hence, information can be distributed and retrieved in a scalable and efficient fashion.
Many ICN related projects have been proposed in the past years. TRIAD [TRIAD], which proposed name-based routing model, and UC Berkeley Data Oriented Network Architecture (DONA) [Koponen07] are earlier ICN affiliated projects. Since then, many research efforts on ICN have been put forward into the research community. In this paper, we will first start with the introduction to the ICN concept, and then follow by recently proposed ICN projects including Name Data Networking (NDN), Network of Information (NetInf), Publish and Subscribe Architecture, Content Mediation Networks (COMET), and CONVERGENCE architecture.
In this section, we introduce a general concept of ICN by providing an overview description of ICN components, which includes the naming scheme, the routing mechanism, and the caching capability.
Information/content unit in ICN is generally called Named Data Object (NDO). NDO can be any kind of digital content such as a video, an image, a document, a webpage, etc, or it can represent a real world object. It consists of a location-independent identifier (name), data, and possibly a metadata, which describes an NDO. The same NDO can be identified by multiple names. An NDO is designed differently in each ICN approach. ICN categorizes the naming scheme into 2 different types [Choi11]. The commonly used schemes are flat and hierarchical naming.
Hierarchical Naming consists of multiple components. The format is similar to the URL i.e. com1/com2/obj, where “/” denotes the boundary between components. Hierarchical naming enhances scalability since name prefix can be aggregated in the same way as the URL. Therefore, It is more coherent to the existing IP networks. The name is user-friendly and conveys meaning to users. Therefore it is easy to remember. However, it imposes security vulnerability since the name is visible and does not bind to a hash.
Flat Naming offers uniqueness and persistency. There are no structure binds to the name. The hash of the content or the hash of the source's key is put as part of the name, which adds self-certifying property. Therefore, the name is not human-friendly. Flat naming has a scalability problem since it does not support routing aggregation. Therefore, the architecture must add additional structure to solve this issue [Ahlgren12].
More recent ICN proposals allow a hybrid naming which mix flat naming and hierarchical naming to take advantage of both schemes.
ICN handles NDO packet routing and forwarding through 2 different methods, Name Resolution (2-step approach), and Name-Based Routing (1-step approach) [Bari12].
Name Resolution approach provides a means for client to search for NDO by name. It consists of 2 steps, the name to source locators (NDO storage) mapping, and the forwarding of request message to the source. This 2-step approach needs additional entity called Name Resolution System (NRS) to provide the translation. The disadvantage of this approach is that NRS can be a point-of-failure, and as a consequense, many NDO registered on that NRS would be inaccessible. Another drawback is that the NRS requires a large storage to store NDO mapping. However, this approach guarantees the finding of the requested NDO since NRS already provides a pointer to the NDO source.
Name-Based Routing is a 1-step approach. NDO request is forwarded by content routers (CR), where CR locally decides the next hop of the NDO request based on NDO name. There are 2 types of routing models [Choi11]. The first is the Unstructured Routing, which is similar to the traditional IP routing with some modification. Therefore, it does not work well when there is NDO movement and when the number of copies of NDOs is large. The second model is the Structured Routing. It uses Distributed Hash Table (DHT) to provide a lookup and routing service. The pros of this method are its ability to scale and a small overhead when changes occur. Name-Based Routing approach does not guarantee the discovery of the NDO since the resolving and forwarding process is done hop-by-hop.
ICN offers caching service to improve the performance of NDO access of the subsequent requests. Multiple copies of NDOs can be distributed across the networks. It can be stored locally on a node's cache or can be a shared on a network cache. Caching can also be classified into in-network caching where the caching is done within the networks, i.e., on the content routers, and the edge caching in which the end nodes store the cache. Furthermore, caching can also be divided into 3 levels based on granularity; object level (complete NDO), chunk level (part of NDO) and packet level (bytes of NDO) [Pavlou13_2]. Each ICN architecture applies different caching granularity, scheme, and policy depending on its design. Overall, caching helps reducing the request traffic towards the source. It also enhances the response time of NDO requests. In the next section, we will discuss in more details about different proposed ICN architectures.
There are many ICN approaches that have been put forward in the past few years. In this section we will give a summary of recent ICN architectures. In each approach, we consider its general concept; the information model, the naming scheme, and the routing and forwarding of NDO request and response.
Network of Information (NetInf) is one of the proposed designs for the future Internet architecture. It was initiated by the European FP7 4WARD project [4WARD], and has been further developed by the SAIL project [SAIL]. In this section, we will focus on the NetInf architecture of the SAIL project.
Two classes of objects are defined in NetInf [Dannewitz09]. 1.) Information Object (IO), which represents the real world object 2.) Data Object (DO) represents a digital object, for example, a Star War movie is an information object, while its encoding, MP4, is the data object. In NetInf information model, each information object can be decomposed into multiple information objects, which mapped to one or more data object. The data object then mapped to one or more locators. This model allows users to access information by specifying a semantic object rather than a host. We will use the term named data object (NDO) as a general term for information object. An NDO in NetInf consists of a unique identifier, a metadata, and the data. Metadata provides description of the data. In many cases, it is used for a security purpose.
SAIL's naming scheme is flat. The name is defined by using a “ni:” and “nih:” URI scheme. Naming in NetInf also provides name-data integrity to ensure that given the name, the retrieved object really corresponds to it. To provide a user-friendlier naming, a mapping system can be provided for translating between “ni:” name and a human-friendly name.
SAIL provides two different models for forwarding user request. In the first model, Name Resolution System (NRS) is used to map the name to its locators indicated where the NDO is stored. NRS uses multilevel DHT to form a hierarchical resolution system, which consists of global NRS and local NRS. The local and global scope helps make sure that the selected locator is always close to the user. In addition, the NRS also keeps track of the user's request and collects request statistics. This information is useful for determining which NDO should be cached locally, and thus speed up the NDO retrieval. Alternatively, in Name-Based Routing model, NDO information is stored and distributed in network routers using a routing protocol. Therefore, NDO request can be directly forwarded to the NDO source. Moreover, SAIL also integrates NRS with Named-Based Routing to support a more flexible mechanism. The hybrid mode allows user to query the NRS, which then responds back with a routing hint. The hint will guide the request towards the NDO source.
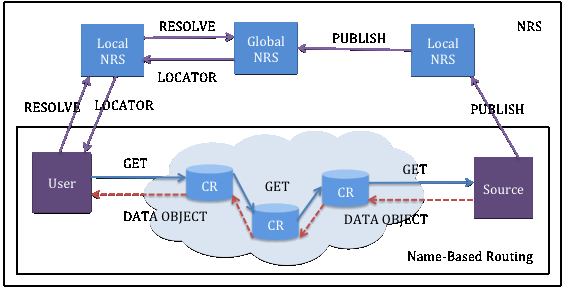
SAIL implements NetInf model on top of the HTTP layer of the TCP/IP stack or on top of a non-IP stack. The NetInf communication layer is called a Convergence Layer (CL). Figure 1 [Xylomenos13] shows the flow of NDO request and its corresponding data response of NRS and Name-Based Routing models. For NRS, A source, who owns a copy of NDO, sends a PUBLISH message to its local NRS. The local NRS then registers the NDO to the global NRS. A client sends a name resolution request to the local NRS. If there is no match, a request is forwarded to global NRS, which returns an NDO locator to the client. The client then requests for an NDO by sending out GET message. The GET message is forwarded by the underlying network to the source. The DATA RESPONSE is then route back from the source to client using the same path. In Named-Base Routing approach, a client sends a GET message directly to the content routers (CR). The router contained NDO information will forward the request to the NDO source.
Named Data Networking (NDN) [NDN] proposed an architecture that is shifted from the current IP model to the data oriented communication. NDN was developed from the proposed Content-Centric Networking (CCN) [Jacobson09].
In NDN, there are two types of packet. An INTEREST packet that client sends out to request for a Named Data Object (NDO). It includes the name specifying the NDO. A DATA packet is a response from the data source. It contains the name, as well as the signature, and the data content. NDN uses a hierarchical scheme for naming. A name can be human-readable or a binary object and is not visible to the networks. Client and source must agree upon name construction so at the end both of them can conclude with the same name. For each NDO, name and data are bonded and attached with a signature to achieve name-data integrity and authenticity.
NDN device provides 3 modules for forwarding, routing packet and caching data [Zhang10]. 1.) Forwarding Information Base (FIB) is a table that provides forwarding information. It directs INTEREST packet toward one or more sources. FIB is generated by a named-based routing protocol. 2.) Pending Interest Table (PIT) collects one or more incoming interfaces of the INTEREST packet so the DATA packet can be delivered back on the same path. 3.) Content Store (CS) is used for caching NDO so the subsequent request can access the data faster.
A client request for an NDO sends out INTEREST packet. When the packet arrives at the NDN node, i.e., server or router, the node checks whether an NDO exists in its content storage or not by checking the NDO name. If there is a match, a DATA packet is sent back to the client. If not, a node will check its PIT table. If the entry exists on a PIT, the INTEREST packet is dropped and the arrival interface of the entry is updated. This means that the client already made an NDO request hence the request will not be forwarded again. On the other hand, if it does not exist, a new arrival interface is added to the PIT. A node then determines where to forward the INTEREST packet by checking the FIB table. When the INTEREST packet reaches the source, the DATA packet is generated and routed back to the client on the same path by using collected route data from PIT. As the DATA packet is forwarded back along the path, the corresponding PIT entry is removed.
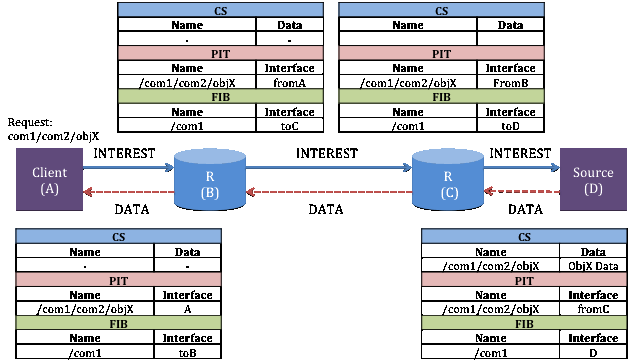
Figure 2 [Xylomenos13] shows NDN message flows. The table includes entries on CS, PIT, and FIB when the INTEREST packet is forwarded hop-by-hop from client to source. The routing process in NDN is hop-by-hop and one request generates one response.
In Publish-Subscribe Architecture, a source publishes information. A client then subscribes to the content it needs. If the information is available, it will be delivered to the client. The Publish-Subscribe Internet Routing Paradigm (PSIRP) [PSIRP] was an earlier ICN model that proposed this architecture and then followed by its successor project, PURSUIT [PURSUIT]. Both PSIRP and PURSUIT are part of the European FP 7 project. In this section, we will present the Publish-Subscribe model of the PURSUIT project.
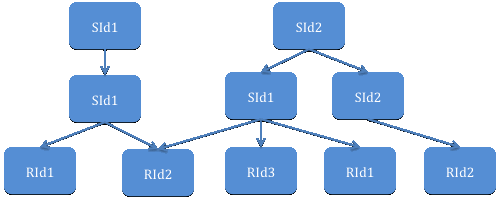
The data unit in PURSUIT is called an information item. Each information item has a pair of identifiers, which are Scope ID (SId) and Rendezvous ID (RId). SId tells which group an information item belongs to, while RId represents each information piece. Each information item must be in at least one scope. The scope provides policy enforcement and access right for each group of information items. Figure 3 [PSIRP] shows a hierarchy of scopes. Naming in PURSUIT follows flat scheme, comprises of sequences of SId(s) and an RId. A name is a path from the root of the tree to the leaf node, which is RId. Same piece of information can be specified by multiple names. For example, SId1/SId1/RId1, or SId2/SId1/RId1 specifies RId1.
Three core functions drive PURSUIT architecture: Rendezvous Function, Topology Function, and Forwarding Function. Rendezvous Function plays a major role in PURSUIT by providing a name resolution function, which maps a subscriber to a publisher. It also initializes the delivery of information item to the client. The Rendezvous Function performs at the Rendezvous Point (RP) on the Rendezvous Node (RN). RNs are structured in hierarchy through Distributed Hash Table (DHT). An RN node is responsible for managing different scope. The Topology Function deploys a routing protocol to collect the topology of its domain and exchange routing information with other domains for global routing. It is operated by Topology Manager (TM). One domain contains one TM. Lastly, Forwarding Function is implemented on the Forwarding Node (FN), which directs the information item to a client. The forwarding mechanism is label-based and uses the Bloom Filter technique to speed up the information delivery. In addition, FN also has caching ability.
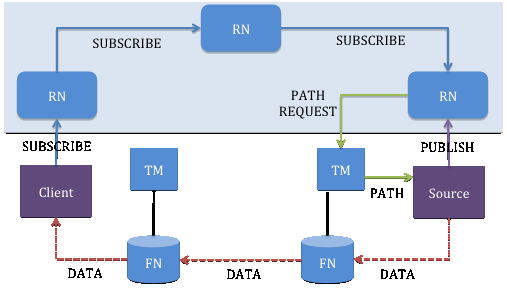
Figure 4 [Ahlgren12] [Xylomenos13] shows the sequence of NDO publish and request in PURSUIT. A source publishes information item (SId, RId) to the RN, who is the owner of the scope. The scope owner RN can be source local RN or RNs in different domain. The client specifies RId and SId in order to request for an information item. It sends out a subscription message via its local RN towards the scope owner RN using RId. The scope owner RN then sends a request to TM to generate a return path and send it to the source, which then uses source routing to deliver NDO to client. The information item is forwarded via FNs, which uses Bloom Filter's Forwarding Identifier (FId) to decide where to send the packet.If a client requests for an information item it asked for before, PURSUIT provides a mechanism to bypass the RN functions, so the request message can be forwarded directly by the FNs to the source using a Bloom Filter's reverse path [Xylomenos13].
COMET [COMET] is another ICN project funded by the European FP 7. Its architecture distinguishes two types of planes. First, the Content Mediation Plane (CMP) that lies between the contents and the physical network layer. The plane tightly connects the two layers together allowing the gain of content awareness (i.e. characteristics of content), server awareness (i.e. server conditions), and network awareness (i.e. topologies and available paths), which helps COMET enhance efficient content retrieval. The second plane is the Content Forwarding Plane (CFP).
CMP is apprehended by a Content Mediation Server (CMS). CMS provides a name resolution function. It maps a name to a list of content sources or caching devices using hierarchical distributed hash table (DHT) or the DNS approach. One content source is then selected based on the awareness information such as content distance, server workload, and network loads. Another component in COMET is the Content Aware Router (CAR). CAR connects to the CMS and performs content forwarding based on CMS instructions. It situates in the CFP plane. Each COMET domain contains at least one CMS.
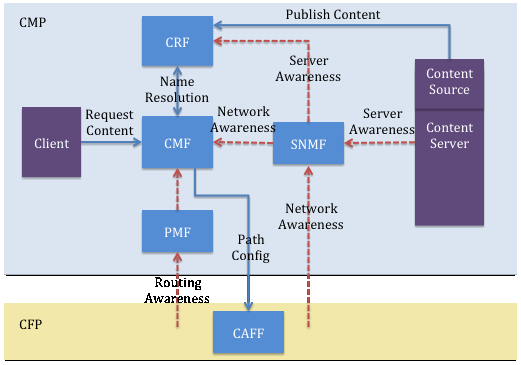
Figure 5 [Pavlou13_1] shows COMET functional blocks and their relationships.
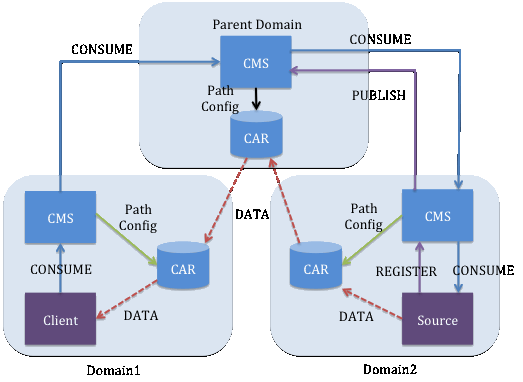
COMET supports two architectures; the Coupled Approach and Decoupled Approach. In the Coupled Approach, name resolution and content delivery are coupled together. A source publishes a new content by sending out a REGISTER message to its local CMS. A local CMS then assigned an identifier to the content and advertises the new content entry to other CMSs by issuing a PUBLISH message to its parent CMSs (COMET domains are structured in hierarchy). The PUBLISH message consists of the content ID, and content location. When a client requests for a content, it sends a CONSUME message to its local CMS. The message is forwarded to the upper-level CMS until the named content is found. Then, the message is sent to the domain where the content resides, and finally to the source. In each CMS, a name resolution is performed. The CMF function decides the best content source for the clients based on awareness information. Finally, CARs deliver the content to the client by using the content delivery tree it stored. The state tree is established during the name resolution by the CMS. Figure 6 [Xylomenos13] presents the flows of request and data message flows of the coupled approach.
For the Decoupled Approach, name resolution is separated from content delivery. CRF function in this case works the same way as the DNS so the content name is a locator. As a result, there is no mobility for the content. In this approach, a source send out a PUBLISH message only to its local CMS. The client also issues a CONSUME message to its CMS. The client CMS will ask its upper-level domain for source CMS location. Then, the client CMS will connect to the source CMS to establish the path from client to source. Client can then use source routing to forward the request message to the source through CARs. The source routes the content to the client using reverse path. The coupled approach is not practical for the information centric architecture.
CONVERGENCE [CONVERGENCE], a European FP7 project is based on the publish-subscribe model. CONVERGENCE introduces VDI (Versatile Digital Item) as its unit of content distribution. VDI acts as a container that holds name, metadata, and resource (data). Metadata in VDI links to a license, which specifies the action that can be performed to the resource. VDI is represented in an XML format.
CONVERGENCE introduces a 3-level architecture [Chiariglione12]. First, the Application Level is part of the semantic overlay. It forms and ingests VDI, which sent and received through the application-middleware interface. The second is the Middleware Level (CoMid). CoMid provides a VDI processing capability, which allows a node to publish or search for a VDI. Lastly, the Computing Platform offers node's communication infrastructure, which is based on the Content Network (CoNet) architecture. In addition, a content security mechanism (CoSec) is also included in this level.
Content Network (CoNet)[Melazzi12] is an ICN underlying infrastructure in which CONVERGENCE exploits to accommodate the publish and subscribe of NDOs. Its approach is fairly similar to the NDN architecture. However, there are some certain concepts that differentiate the two models. CoNet deploys hierarchical naming scheme. Each name composes of a sequence of components for example, /domainName/objectName/ChunkName. The data source split contents into chunks, each of them specified by name. Therefore, in order to retrieve the complete content, a client need to send out a stream of requests to the source to fetch all chunks.
CoNet composes of multiple CoNet subsystem (CSS), which contains CoNet nodes. There are different approaches for CoNet implementations such as CoNet on top of L3 (IP), CoNet on top of L2, and CoNet L3 integration. CoNet Information Unit (CIU) consists of 2 types. An Interest CIU is sent out to request for an NDO from the sources or caches, and the Data CIU that carries the NDO and delivers it to the client. All types of CIU are transported by the CoNet's carrier-packets.
There are 5 types of CoNet components defined: 1.) End Node (EN) is a client device that requests for an NDO by sending out Interest CIU. 2.) Serving Node (SN) splits the data into chunks and then deliver the data chunk through the Data CIU. 3.) Border Node (BN) helps forward the carrier-packets using name-based routing protocol. It also stores cached NDO and connects 2 CSSs together 4.) Internal Node (IN) provides an in-network caching capability. It sits in between the BNs in the CSS and is optional for the deployment. 5.) Name Routing System Node (NRS), also offers name-based routing service.
The Lookup and Cache Concept allows nodes to forward carrier-packets to the right destination. A Forwarding Information Base (FIB), resides in BN, contains an active forwarding information i.e. route that are frequently used. When an Interest ICU arrives, a name prefix matching is performed. If there is no matching entry in FIB, FIB will send a name lookup request to a Routing Information Base (RIB) located on the NRS. RIB holds a complete set of routing information and responds to FIB query. In the case that FIB cannot find a matching entry, and its table is already full, FIB uses a routing replacement algorithm to determine its action. It can either do nothing and drop the Interest packet or query a new entry from RIB and replace the old entry with the new one. FIB uses algorithm such as Inactive Timeout Estimation to replace the least recently used entry. Too many lookups can incur delay and increase NRS workload.
FIB in CONVERGENCE performs the same function as in NDN, but it contains a smaller set of routing information i.e. the active ones, and consults with RIB when necessary. The two level of routing information storage helps saving cost since a large number of FIBs can be made small and cheap, with only a few large and expensive RIBs provided. After the Interest CIU reaches the source or the caching devices, the Data CIU is routed back through the reverse path using the forwarding information collected by the Interest CIU as it traveled upstream. This is another point that varies CONVERGENCE from NDN since NDN uses PIT entry to route Data packet back to the requester.
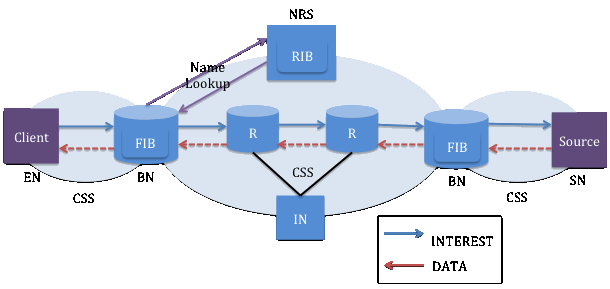
Figure 7 [Xylomenos13] shows CONVERGENCE CIUs flows. The Interest CIU is sent from client towards the data source or the caching device. BNs forward the Interest CIU based on information on FIB. FIB can consults with RIB when it cannot find a forwarding entry. Between BNs, network routers are responsible for forwarding Interest CIU to destination BN. When the Interest CIU reaches source, the Data CIU is sent on the reverse path. On the way to client, the data can be cached on the BNs and INs.
The architecture of the Internet has shifted from the traditional TCP/IP based to the content oriented networks where information is disseminated in a more efficient manner and located closer to the users. The paper presents a survey on 5 ICN projects proposed in the past few years (2010 to present). We focus mainly on the naming scheme and routing mechanism of each approach. Table1 [Xylomenos13] [Ahlgren12] provides a summary of different ICN Approaches. NDN and CONVERGENCE uses a hierarchical naming and name-based routing. The hierarchical naming allows name to be aggregated and hence accommodate a large name space. However, with name-based routing, each content router will have to handle a large amount of routing entries. SAIL (NetInf) and PURSUIT (Publish-Subscribe Architecture) applies a flat scheme and name resolution. The main issue of flat naming is scalability. To solve this problem, both SAIL and PURSUIT provide Distributed Hash Tables (DHT) to form a hierarchy of name resolution. In addition, SAIL and PURSUIT also use name-based routing for content delivery. COMET does not clearly specify its naming scheme, but it supports a name resolution mechanism using scope hierarchy provided by the Content Mediation Plane. It also uses content routers to provide name-based routing mechanism.
| Approach | Predecessor | Naming | Routing |
| SAIL (NetInf) | 4WRAD | Flat | Name Resolution (Using NRS and Multilevel DHT) Name-Based Routing |
| NDN | CCN | Hierarchical | Name-Based Routing (Using FIB and PIT) |
| PURSUIT (Publish-Subscribe) | PSIRP | Flat | Name Resolution (Using Rendezvous Function) Name-Based Routing (Using Topology and Forwarding Functions) |
| COMET | - | - | Name Resolution (Using CMSs provided by CMP ) Name-Based Routing (Using CARs provided by CMF) |
| CONVERGENCE | CoNet | Hierarchical | Name-Based Routing (Using FIB and RIB) |
| [Ahlgren12] | B. Ahlgren; C. Dannewit; C. Imbrenda; D. Kutscher; B.
Ohlman,“A Survey of Information-Centric Networking,” IEEE Comm Mag,
vol. 50, no. 7, 2012, pp. 26-36. http://ieeexplore.ieee.org/document/6231276/ |
| [Xylomenos13] | G. Xylomenos; C. Ververidis; V. Siris; N. Fotiou; C.
Tsilopoulo; X. Vasilakos; K. Katsaros; G. Polyzos, “A Survey of
Information-Centric Networking Research,” Communications Surveys
& Tutorials, IEEE , vol. PP, no.99, pp. 1-26. http://ieeexplore.ieee.org/document/6563278/ |
| [Bari12] | M.F. Bari; S. Chowdhury; R. Ahmed; R. Boutaba; B.
Mathieu, “A survey of Naming and Routing in Information Centric
Networks,” IEEE Comm Mag, vol. 50, no. 12, 2012, pp. 44-53. http://ieeexplore.ieee.org/document/6384450/ |
| [Haque13] | M. Ul Haque; A. Willig; K. Pawlikowski; L. Bischofs,
“Name-based routing for information centric future internet
architectures,” Ubiquitous and Future Networks (ICUFN), 2013 Fifth
International Conference on, 2013, pp. 517-522. http://ieeexplore.ieee.org/document/6614874/ |
| [Choi11] | J. Choi; J. Han; E. Cho; T. Kwon; Y. Choi, “A Survey on
Content-Oriented Networking For Efficient Content Delivery,” IEEE Comm
Mag, vol. 49, no. 3, 2011, pp.121-127. http://ieeexplore.ieee.org/document/5723809/ |
| [SAIL] | “SAIL Project,” http://www.sail-project.eu/ SAIL project includes publications and deliverables of SAIL architecture and design |
| [Zhang10] | L. Zhang; D. Estrin; J. Burke; V. Jacobson; J. D.
Thornton; D. K. Smetters; B. Zhang; G. Tsudik; k. claffy; D. Krioukov;
D. Massey; C. Papadopoulos, T. Abdelzaher; L. Wang; P. Crowley; E. Yeh,
“Named Data Networking (NDN) Project,” PARC, Tech. Rep. NDN-0001, 2010. http://www.named-data.net/techreport/TR001ndn-proj.pdf |
| [PURSUIT] | “PURSUIT Project,” http://www.fp7-pursuit.eu/PursuitWeb/ PURSUIT project includes publications and technical reports of PURSUIT architecture and design |
| [PSIRP] | “PSIRP Project,” http://www.psirp.org/ PSIRP project includes publications and technical reports of PSIRP architecture and design |
| [COMET] | “COMET Project,” http://www.comet-project.org/ COMET project includes publications and deliverables of COMET architecture and design |
| [Pavlou13_1] | G. Pavlou; N. Wang; W. K. Chai; I. Psaras,
“Internet-Scale Content Mediation in Information-Centric Networks,”
Annals of Telecommunications, Special Issue on Networked Digital Media,
vol. 68, no. 3-4, 2013, pp. 167-177. http://epubs.surrey.ac.uk/730264/1/Internet-scale%20content %20mediation%20in%20information-centric%20networks.pdf |
| [Melazzi12] | N. B. Melazzi; A. Detti; M. Pomposini; S. Salsano,
“Route Discovery and Caching: A Way to Improve the Scalability of
Information-Centric Networking,” IEEE Global Communications Conference,
2012, pp.2701-2707. http://netgroup.uniroma2.it/Andrea_Detti/papers/conferences/ICN-globecom-2012.pdf |
| [CONVERGENCE] | “CONVERGENCE Project,” http://www.ict-convergence.eu/dissemination/ CONVERGENCE project includes publications and deliverables of CONVERGENCE architecture and design |
| [Chiariglione12] | L. Chiariglione; A. Difino; N. Blefari Melazzi; S.
Salsano; A. Detti; G. Tropea; A.C.G. Anadiotis; A.S. Mousas; I.S.
Venieris; C.Z. Patrikakis, “Publish/Subscribe over Information Centric
Networks: a Standardized Approach in CONVERGENCE,” Future Network
&Mobile Summit, 2012. http://netgroup.uniroma2.it/Stefano_Salsano/papers/salsano-futint-mobsumm-12-ps- icn-convergence.pdf |
| [Pavlou13_2] | G. Pavlou,“Information-Centric Networking and
In-Network Cache Management: Overview, Trends and Challenges,”
IFIP/IEEE CNSM , 2013. http://www.cnsm-conf.org/2013/documents/CNSM2013-Keynot2-G-Pavlou.pdf |
| [Jacobson09] | V. Jacobson; D.K. Smetters; J.D. Thornton; M.F. Plass;
N.H. Briggs; R.L. Braynard. “Networking named content,” In Proceedings
of the 5th International Conference on Emerging Networking Experiments
and Technologies, 2009, pp. 1-12. http://conferences.sigcomm.org/co-next/2009/papers/Jacobson.pdf |
| [Dannewitz09] | C. Dannewitz, “NetInf: An Information-Centric Design
for the Future Internet”, In Proc. 3rd GI/ITG KuVS Workshop on The
Future Internet, May 2009. https://www.cs.uni-paderborn.de/fileadmin/Informatik/AG-Karl/Publications/KuVS- NetInf-Dannewitz.pdf |
| [NDN] | “NDN Project,” http://named-data.net/ NDN project includes publications and technical reports of NDN architecture and design |
| [4WARD] | “4WARD Project,” http://www.4ward-project.eu/ 4WARD project includes publications and deliverables of 4WARD architecture and design |
| [Koponen07] | T. Koponen; M. Chawla; B. Chun; A. Ermolinskiy; K. H.
Kim; S. Shenker; I. Stoica, “A data-oriented (and beyond) network
architecture,” in ACM SIGCOMM, 2007, pp. 181-192. http://www.cs.iastate.edu/~yingcai/cs587x/reading08/PatrickCarlson.pdf |
| [TRIAD] | “TRIAD project,” http://gregorio.stanford.edu/triad/ Triad project provides details of TRIAD name-based routing protocol |
| BN | Border Node |
| CAFF | Content Aware Forwarding Function |
| CBCB | Combine Broadcast and Content Based Routing |
| CDN | Content Delivery Networks |
| CFP | Content Forwarding Plane |
| CIU | CoNet Information Unit |
| CL | Convergence Layer |
| CMF | Content Mediation Function |
| CMP | Content Mediation Plane |
| CMS | Content Mediation Server |
| CNN | Content-Centric Networking |
| COMET | Content Mediator Architecture for Content-Aware NETworks |
| CoMid | Content Middleware |
| CoNet | Content Network |
| CoSec | Content Security |
| CRF | Content Resolution Function |
| CR | Content Router |
| CS | Content Store |
| CSS | CoNet Subsystem |
| DHT | Distributed Hash Table |
| DNS | Domain Name Server |
| DO | Data Object |
| EN | End Node |
| FIB | Forwarding Information Base |
| FId | Forwarding Identifier |
| FN | Forwarding Node |
| ICN | Information Centric Networking |
| IN | Internal Node |
| IO | Information Object |
| IP | Internet Protocol |
| L2 | Layer 2 of TCP/IP protocol |
| L3 | Layer 3 of TCP/IP protocol |
| NDN | Named Data Networking |
| NDO | Named Data Object |
| NetInf | Network of Information |
| ni | Named Information |
| nih | Named Information for Human |
| NRS | Name Resolution System |
| P2P | Peer-to-Peer |
| PIT | Pending Interest Buffer |
| PMF | Path Management Function |
| PSIRP | Publish-Subscribe Internet Routing Paradigm |
| RIB | Routing Information Base |
| RId | Rendezvous Identifier |
| RN | Rendezvous Node |
| RP | Rendezvous Point |
| SAIL | Scalable and Adaptive Internet Solutions |
| SId | Scope Identifier |
| SN | Serving Node |
| SNMF | Server and Network Monitoring Function |
| TCP/IP | Transmission Control Protocol/Internet Protocol |
| TM | Topology Manager |
| TRIAD | Translating Relaying Internet Architecture integrating Active Directories |
| URI | Uniform Resources Identifier |
| URL | Uniform Resource Locator |
| VDI | Versatile Digital Item |
| XML | Extensible Markup Language |