 |
Rohit Goyal, Raj Jain, Shiv Kalyanaraman, Sonia Fahmy, Bobby Vandalore
Department of Computer and Information Science,
395 Dreese Lab, 2015 Neil Avenue
The Ohio State University
Columbus, OH 43210-1277
E-mail: goyal@cse.wustl.edu
Phone: (614)-688-4482. Fax: (614)-292-2911
Abstract
In this paper we study the design issues for improving TCP performance over the ATM UBR service. ATM-UBR switches respond to congestion by dropping cells when their buffers become full. TCP connections running over UBR can experience low throughput and high unfairness. Intelligent switch drop policies and end-system policies can improve the performance of TCP over UBR with limited buffers. We describe the various design options available to the network as well as to the end systems to improve TCP performance over UBR. We study the effects of Early Packet Discard, and present a per-VC accounting based buffer management policy. We analyze the performance of the buffer management policies with various TCP end system congestion control policies including slow start and congestion avoidance, fast retransmit and recovery and selective acknowledgments. We present simulation results for various small and large latency configurations with varying buffer sizes and number of sources.
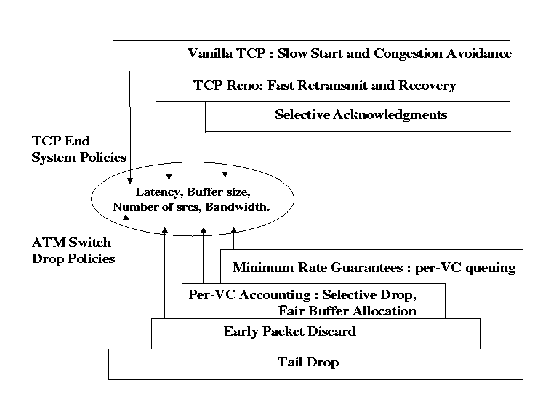
Figure 1illustrates a framework for the various design options available to networks and end-systems for congestion control. Intelligent drop policies at switches can be used to improve throughput of transport connections. Early Packet Discard (EPD) [ 19] has been shown to improve TCP throughput but not fairness [ 5]. Enhancements that perform intelligent cell drop policies at the switches need to be developed for UBR to improve transport layer throughput and fairness. A policy for selective cell drop based on per-VC buffer management can be used to improve fairness. Providing guaranteed minimum rate to the UBR traffic has also been discussed as a possible candidate to improve TCP performance over UBR.
In addition to network based drop policies, end-to-end flow control and congestion control policies can be effective in improving TCP performance over UBR. The fast retransmit and recovery mechanism [ 6], can be used in addition to slow start and congestion avoidance to quickly recover from isolated segment losses. The selective acknowledgments (SACK) option has been proposed to recover quickly from multiple segment losses. A change to TCP's fast retransmit and recovery has also been suggested in [ 2] and [ 9].
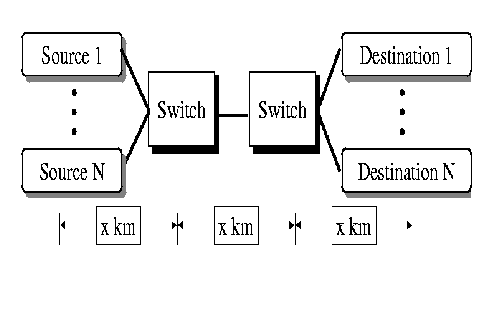
In this paper, we propose a per-VC buffer management scheme called Selective Drop to improve TCP performance over UBR. This scheme is simpler than the Fair Buffer Allocation (FBA) scheme proposed in [ 8]. We present an analysis of the operation of these schemes and the effects of their parameters. We also provide guidelines for choosing the best parameters for FBA and Selective Drop. We then present simulation results for TCP over the various UBR enhancements. Although, other buffer management schemes have been presented in recent literature, their performance has not been evaluated with the various TCP congestion control options, and for different latencies. We evaluate the performance of the enhancements to UBR, as well as to TCP congestion control mechanisms. We study the performance and interoperability of the network and the end-system enhancements for low latency and large latency configurations.
We first discuss the congestion control mechanisms in the TCP protocol and explain why these mechanisms can result in low throughput during congestion. We then describe our simulation setup used for all our experiments and define our performance metrics. We present the performance of TCP over vanilla UBR and explain why TCP over vanilla UBR results in poor performance. Section 4describes in detail, the enhancements to the UBR service category and our implementations. These enhancements include EPD, Selective Drop and Fair Buffer Allocation. Section 5describes the enhancements to TCP including fast retransmit and recovery, New Reno, and Selective Acknowledgments. We describe our implementations, and present our simulation results for the TCP modifications with each of the UBR changes. Section 7presents a summary and ideas for future work.
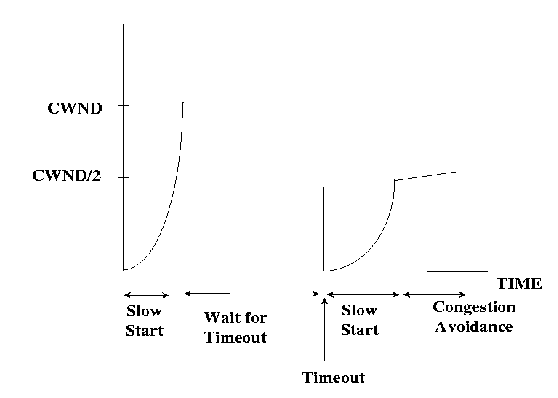
The basic TCP congestion control scheme (we will refer to this as vanilla TCP) consists of the ``Slow Start'' and ``Congestion Avoidance'' phases. The variable SSTHRESH is maintained at the source to distinguish between the two phases. The source starts transmission in the slow start phase by sending one segment (typically 512 Bytes) of data, i.e., CWND = 1 TCP segment. When the source receives an acknowledgment for a new segment, the source increments CWND by 1. Since the time between the sending of a segment and the receipt of its ack is an indication of the Round Trip Time (RTT) of the connection, CWND is doubled every round trip time during the slow start phase. The slow start phase continues until CWND reaches SSTHRESH (typically initialized to 64K bytes) and then the congestion avoidance phase begins. During the congestion avoidance phase, the source increases its CWND by 1/CWND every time a segment is acknowledged. The slow start and the congestion avoidance phases correspond to an exponential increase and a linear increase of the congestion window every round trip time respectively.
If a TCP connection loses a packet, the destination responds by sending duplicate acks for each out-of-order packet received. The source maintains a retransmission timeout for the last unacknowledged packet. The timeout value is reset each time a new segment is acknowledged. The source detects congestion by the triggering of the retransmission timeout. At this point, the source sets SSTHRESH to half of CWND. More precisely, SSTHRESH is set to max{2, min{CWND/2, RCVWND}}. CWND is set to one segment size.
As a result, CWND < SSTHRESH and the source enters the slow start phase. The source then retransmits the lost segment and increases its CWND by one every time a new segment is acknowledged. It takes
![]() RTTs from the point when the congestion was detected, for CWND to reach the target value of half its original size (
RTTs from the point when the congestion was detected, for CWND to reach the target value of half its original size (
![]() ). Here MSS is the TCP maximum segment size value in bytes. This behavior is unaffected by the number of segments lost from a particular window.
). Here MSS is the TCP maximum segment size value in bytes. This behavior is unaffected by the number of segments lost from a particular window.
If a single segment is lost, and if the receiver buffers out of order segments, then the sender receives a cumulative acknowledgment and recovers from the congestion. Otherwise, the sender attempts to retransmit all the segments since the lost segment. In either case, the sender congestion window increases by one segment for each acknowledgment received, and not for the number of segments acknowledged. The recovery behavior corresponds to a go-back-N retransmission policy at the sender. Note that although the congestion window may increase beyond the advertised receiver window (RCVWND), the source window is limited by the minimum of the two. The typical changes in the source window plotted against time are shown in Figure 2.
Most TCP implementations use a 500 ms timer granularity for the retransmission timeout. The TCP source estimates the Round Trip Time (RTT) of the connection by measuring the time (number of ticks of the timer) between the sending of a segment and the receipt of the ack for the segment. The retransmission timer is calculated as a function of the estimates of the average and mean-deviation of the RTT [ 10]. Because of coarse grained TCP timers, when there is loss due to congestion, significant time may be lost waiting for the retransmission timeout to trigger. Once the source has sent out all the segments allowed by its window, it does not send any new segments when duplicate acks are being received. When the retransmission timeout triggers, the connection enters the slow start phase. As a result, the link may remain idle for a long time and experience low utilization.
Coarse granularity TCP timers and retransmission of segments by the go-back-N policy are the main reasons that TCP sources can experience low throughput and high file transfer delays during congestion.
The performance of TCP over UBR is measured by the efficiency and fairness which are defined as follows. Let x i be the throughput of the ith TCP source (0 < i< N, where Nis the total number of TCP sources). Let Cbe the maximum TCP throughput achievable on the link. Let Ebe the efficiency of the network. Then, Eis defined as
The TCP throughputs x i s are measured at the destination TCP layers. Throughput is defined as the total number of bytes delivered to the destination application divided by the total simulation time. The results are reported in Mbps.
The maximum possible TCP throughput Cis the throughput attainable by the TCP layer running over UBR on a 155.52 Mbps link. For 512 bytes of data (TCP maximum segment size), the ATM layer receives 512 bytes of data + 20 bytes of TCP header + 20 bytes of IP header + 8 bytes of LLC header + 8 bytes of AAL5 trailer. These are padded to produce 12 ATM cells. Thus, each TCP segment results in 636 bytes at the ATM Layer. From this, the maximum possible throughput = 512/636 = 80.5% = 125.2 Mbps approximately on a 155.52 Mbps link. For ATM over SONET, this number is further reduced to 120.5 Mbps.
Fairness is measured by the Fairness Index Fdefined by:
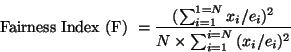
where e
i
is the expected value (fair share) of the throughput for source i. For the n-source configuration, e
i
is simply an equal share of the total link capacity. Thus, the fairness index metric applies well to our n-source symmetrical configurations. In general, for a more complex complex configuration, the value of e
i
can be derived from a more rigorous formulation of a fairness definition that provides max-min fairness to the connections. Note that when
![]() then fairness index = 1. Also, low values of the fairness index represent high unfairness among the connections. The desired values of the fairness index must be close to 1. We consider a fairness index of 0.99 to be near perfect. A fairness index of 0.9 may or may not be acceptable depending on the application and the number of sources involved. Details on the fairness metric can be found in [
13].
then fairness index = 1. Also, low values of the fairness index represent high unfairness among the connections. The desired values of the fairness index must be close to 1. We consider a fairness index of 0.99 to be near perfect. A fairness index of 0.9 may or may not be acceptable depending on the application and the number of sources involved. Details on the fairness metric can be found in [
13].
Column 4 of tables 1and 2show the efficiency and fairness values respectively for these experiments. Several observations can be made from these results.
| Config- | Number of | Buffer | UBR | EPD | Selective | FBA |
| uration | Sources | Size (cells) | Drop | |||
| LAN | 5 | 1000 | 0.21 | 0.49 | 0.75 | 0.88 |
| LAN | 5 | 3000 | 0.47 | 0.72 | 0.90 | 0.92 |
| LAN | 15 | 1000 | 0.22 | 0.55 | 0.76 | 0.91 |
| LAN | 15 | 3000 | 0.47 | 0.91 | 0.94 | 0.95 |
| Column Average | 0.34 | 0.67 | 0.84 | 0.92 | ||
| WAN | 5 | 12000 | 0.86 | 0.90 | 0.90 | 0.95 |
| WAN | 5 | 36000 | 0.91 | 0.81 | 0.81 | 0.81 |
| WAN | 15 | 12000 | 0.96 | 0.92 | 0.94 | 0.95 |
| WAN | 15 | 36000 | 0.92 | 0.96 | 0.96 | 0.95 |
| Column Average | 0.91 | 0.90 | 0.90 | 0.92 | ||
| Config- | Number of | Buffer | UBR | EPD | Selective | FBA |
| uration | Sources | Size (cells) | Drop | |||
| LAN | 5 | 1000 | 0.68 | 0.57 | 0.99 | 0.98 |
| LAN | 5 | 3000 | 0.97 | 0.84 | 0.99 | 0.97 |
| LAN | 15 | 1000 | 0.31 | 0.56 | 0.76 | 0.97 |
| LAN | 15 | 3000 | 0.80 | 0.78 | 0.94 | 0.93 |
| Column Average | 0.69 | 0.69 | 0.92 | 0.96 | ||
| WAN | 5 | 12000 | 0.75 | 0.94 | 0.95 | 0.94 |
| WAN | 5 | 36000 | 0.86 | 1 | 1 | 1 |
| WAN | 15 | 12000 | 0.67 | 0.93 | 0.91 | 0.97 |
| WAN | 15 | 36000 | 0.77 | 0.91 | 0.89 | 0.97 |
| Column Average | 0.76 | 0.95 | 0.94 | 0.97 | ||
Buffer Requirements
TCP performs best when there is zero loss. In this situation, TCP is able to fill the pipe and fully utilize the link bandwidth. During the exponential rise phase (slow start), TCP sources send out two segments for every segment that is acked. For N TCP sources, in the worst case, a switch can receive a whole window's worth of segments from N-1 sources while it is still clearing out segments from the window of the Nth source. As a result, the switch can have buffer occupancies of up to the sum of all the TCP maximum sender window sizes.
| Number of | Configuration | Efficiency | Fairness | Maximum Queue |
| Sources | (Cells) | |||
| 5 | LAN | 1 | 1 | 7591 |
| 15 | LAN | 1 | 1 | 22831 |
| 5 | WAN | 1 | 1 | 59211 |
| 15 | WAN | 1 | 1 | 196203 |
Table
3contains the simulation results for TCP running over the UBR service with infinite buffering. The maximum queue length numbers give an indication of the buffer sizes required at the switch to achieve zero loss for TCP. The connections achieve 100% of the possible throughput and perfect fairness. For the five source LAN configuration, the maximum queue length is 7591 cells = 7591 / 12 segments = 633 segments
![]() 323883 Bytes. This is approximately equal to the sum of the TCP window sizes (65535
323883 Bytes. This is approximately equal to the sum of the TCP window sizes (65535
![]() 5 bytes = 327675 bytes). For the five source WAN configuration, the maximum queue length is 59211 cells = 2526336 Bytes. This is slightly
less that the sum of the TCP window sizes (600000
5 bytes = 327675 bytes). For the five source WAN configuration, the maximum queue length is 59211 cells = 2526336 Bytes. This is slightly
less that the sum of the TCP window sizes (600000
![]() 5 = 3000000 Bytes). This is because the switch has 1 RTT to clear out almost 500000 bytes of TCP data (at 155.52 Mbps) before it receives the next window of data. In any case, the increase in buffer requirements is proportional to the number of sources in the simulation. The maximum queue is reached just when the TCP connections reach the maximum window. After that, the window stabilizes and TCP's self clocking congestion mechanism puts one segment into the network for each segment that leaves the network. For a switch to guarantee zero loss for TCP over UBR, the amount of buffering required is equal to the sum of the TCP maximum window sizes for all the TCP connections.Note that the maximum window size is determined by the minimum of the sender's congestion window and the receiver's window.
5 = 3000000 Bytes). This is because the switch has 1 RTT to clear out almost 500000 bytes of TCP data (at 155.52 Mbps) before it receives the next window of data. In any case, the increase in buffer requirements is proportional to the number of sources in the simulation. The maximum queue is reached just when the TCP connections reach the maximum window. After that, the window stabilizes and TCP's self clocking congestion mechanism puts one segment into the network for each segment that leaves the network. For a switch to guarantee zero loss for TCP over UBR, the amount of buffering required is equal to the sum of the TCP maximum window sizes for all the TCP connections.Note that the maximum window size is determined by the minimum of the sender's congestion window and the receiver's window.
For smaller buffer sizes, efficiency typically increases with increasing buffer sizes (see table 1). Larger buffer sizes result in more cells being accepted before loss occurs, and therefore higher efficiency. This is a direct result of the dependence of the buffer requirements to the sum of the TCP window sizes. The buffer sizes used in the LAN simulations reflect the typical buffer sizes used by other studies of TCP over ATM ([ 3, 14, 16]), and implemented in ATM workgroup switches.
The EPD algorithm used in our simulations is the one suggested by [ 16, 17]. Column 5 of tables 1and 2show the efficiency and fairness respectively of TCP over UBR with EPD. The switch thresholds are selected so as to allow one entire packet from each connection to arrive after the threshold is exceeded. We use thresholds of Buffer Size - 200 cells in our simulations. 200 cells are enough to hold one packet each from all 15 TCP connections. This reflects the worst case scenario when all the fifteen connections have received the first cell of their packet and then the buffer occupancy exceeds the threshold.
Tables 1and 2show that EPD improves the efficiency of TCP over UBR, but it does not significantly improve fairness.This is because EPD indiscriminately discards complete packets from all connections without taking into account their current rates or buffer utilizations. When the buffer occupancy exceeds the threshold, all new packets are dropped. There is a more significant improvement in fairness for WANs because of the relatively larger buffer sizes.
Selective Drop keeps track of the activity of each VC by counting the number of cells from each VC in the buffer. A VC is said to be active if it has at least one cell in the buffer. A fair allocation is calculated as the current buffer occupancy divided by number of active VCs.
Let the buffer occupancy be denoted by X, and the number of active VCs be denoted by N a . Then the fair allocation or fair share Fsfor each VC is given by,
The ratio of the number of cells of a VC in the buffer to the fair allocation gives a measure of how much the VC is overloading the buffer i.e., by what ratio it exceeds the fair allocation. Let Y i be the number of cells from VC i in the buffer. Then the Load Ratio, L i , of VC i is defined as
If the load ratio of a VC is greater than a parameter Z, then new packets from that VC are dropped in preference to packets of a VC with load ratio less than Z. Thus, Zis used as a cutoff for the load ratio to indicate that the VC is overloading the switch.
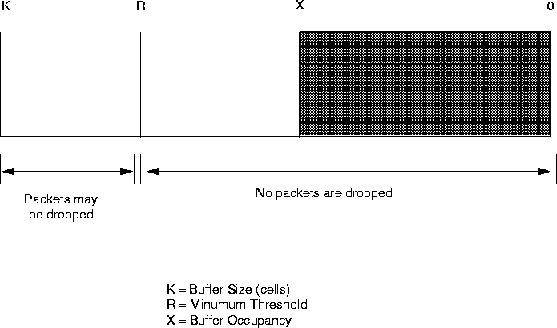
Figure 4illustrates the drop conditions for Selective Drop. For a given buffer size K(cells), the selective drop scheme assigns a static minimum threshold parameter R(cells). If the buffer occupancy Xis less than or equal to this minimum threshold R, then no cells are dropped. If the buffer occupancy is greater than R, then the next new incoming packet of VC i is dropped if the load ratio of VC i is greater than Z.
We performed simulations to find the value of Zthat optimizes the efficiency and fairness values. We first performed 5 source LAN simulations with 1000 cell buffers. We set Rto 0.9
![]() the buffer size K. This ensured that there was enough buffer space to accept incomplete packets during congestion. We experimented with values of Z= 2, 1, 0.9, 0.5 and 0.2. Z= 0.9 resulted in good performance. Further simulations of values of Zaround 0.9 showed that Z= 0.8 produces the best efficiency and fairness values for this configuration. For WAN simulations, any Zvalue between 0.8 and 1 produced the best results.
the buffer size K. This ensured that there was enough buffer space to accept incomplete packets during congestion. We experimented with values of Z= 2, 1, 0.9, 0.5 and 0.2. Z= 0.9 resulted in good performance. Further simulations of values of Zaround 0.9 showed that Z= 0.8 produces the best efficiency and fairness values for this configuration. For WAN simulations, any Zvalue between 0.8 and 1 produced the best results.
The Fair Buffer Allocation Scheme proposed by [
8] uses a more complex form of the parameter Z and compares it with the load ratio L
i
of a VC. To make the cutoff smooth, FBA uses the current load level in the switch. The scheme compares the load ratio of a VC to another threshold that determines how much the switch is congested. For a given buffer size K, the FBA scheme assigns a static Minimum Threshold parameter R(cells). If the buffer occupancy Xis less than or equal to this minimum threshold R, then no cells are dropped. When the buffer occupancy is greater than R, then upon the arrival of every new packet, the load ratio of the VC (to which the packet belongs) is compared to an allowable drop threshold Tcalculated as
In this equation Zis a linear scaling factor. The next packet from VC
i
is dropped if
Figure 4shows the switch buffer with buffer occupancies Xrelative to the minimum threshold Rand the buffer size Kwhere incoming TCP packets may be dropped.
Note that when the current buffer occupancy Xexceeds the minimum threshold R, it is not always the case that a new packet is dropped. The load ratio in the above equation determines if VC
i
is using more than a fair amount of buffer space. X/ N
a
is used as a measure of a fair allocation for each VC, and
![]() is a drop threshold for the buffer. If the current buffer occupancy (Y
i
is greater than this dynamic threshold times the fair allocation (X/ N
a
), then the new packet of that VC is dropped.
is a drop threshold for the buffer. If the current buffer occupancy (Y
i
is greater than this dynamic threshold times the fair allocation (X/ N
a
), then the new packet of that VC is dropped.
Effect of the minimum drop threshold R
The load ratio threshold for dropping a complete packet is Z((K- R)/(X- R)). As Rincreases for a fixed value of the buffer occupancy X, X- Rdecreases, which means that the drop threshold ((K- R)/(X- R)) increases and each connection is allowed to have more cells in the buffer. Higher values of Rprovide higher efficiency by allowing higher buffer utilization. Lower values of Rshould provide better fairness than higher values by dropping packets earlier.
Effect of the linear scale factor Z
The parameter Zscales the FBA drop threshold by a multiplicative factor. Zhas a linear effect on the drop threshold, where lower values of Zlower the threshold and vice versa. Higher values of Zshould increase the efficiency of the connections. However, if Zis very close to 1, then cells from a connection may not be dropped until the buffer overflows.
We performed a full factorial experiment [ 13] with the following parameter variations for both LANs and WANs. Each experiment was performed for N-source configuration.
A set of 54 experiments were conducted to determine the values of Rand Zthat maximized efficiency and fairness among the TCP sources. We sorted the results with respect to the efficiency and fairness values. The following observations can be made from the simulation results (see [ 6]).
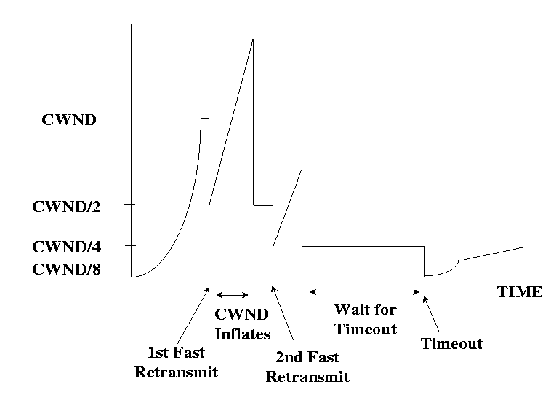
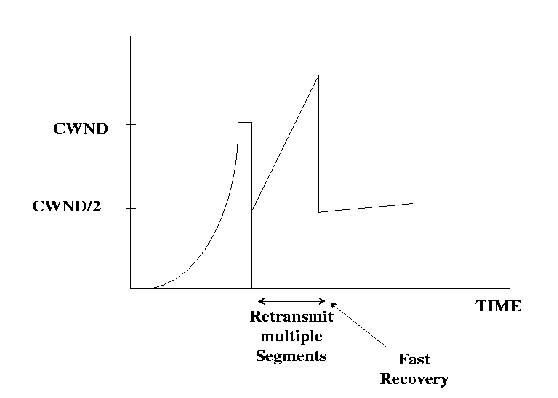
When a TCP receives an out-of-order segment, it immediately sends a duplicate acknowledgment to the sender. When the sender receives three duplicate ACKs, it concludes that the segment indicated by the ACKs has been lost, and immediately retransmits the lost segment. The sender then reduces its CWND by half (plus 3 segments) and also saves half the original CWND value in SSTHRESH. Now for each subsequent duplicate ACK, the sender inflates CWND by one and tries to send a new segment. Effectively, the sender waits for half a round trip before sending one segment for each subsequent duplicate ACK it receives. As a result, the sender maintains the network pipe at half of its capacity at the time of fast retransmit. This is called ``Fast Retransmit.''
Approximately one round trip after the missing segment is retransmitted, its ACK is received (assuming the retransmitted segment was not lost). At this time, instead of setting CWND to one segment and proceeding to do slow start, the TCP sets CWND to SSTHRESH, and then does congestion avoidance. This is called ``Fast Recovery.''
When a single segment is lost from a window, Reno TCP recovers within approximately one RTT of knowing about the loss or two RTTs after the lost packet was first sent. The sender receives three duplicate ACKS one RTT after the dropped packet was sent. It then retransmits the lost packet. For the next round trip, the sender receives duplicate ACKs for the whole window of packets sent after the lost packet. The sender waits for half the window and then transmits a half window worth of new packets. All of this takes one RTT after which the sender receives a new ACK acknowledging the retransmitted packet and the entire window sent before the retransmission. CWND is set to half its original value and congestion avoidance is performed.
| Config- | Number of | Buffer | UBR | EPD | Selective | FBA |
| uration | Sources | Size (cells) | Drop | |||
| LAN | 5 | 1000 | 0.53 | 0.97 | 0.97 | 0.97 |
| LAN | 5 | 3000 | 0.89 | 0.97 | 0.97 | 0.97 |
| LAN | 15 | 1000 | 0.42 | 0.97 | 0.97 | 0.97 |
| LAN | 15 | 3000 | 0.92 | 0.97 | 0.97 | 0.97 |
| Column Average | 0.69 | 0.97 | 0.97 | 0.97 | ||
| WAN | 5 | 12000 | 0.61 | 0.79 | 0.8 | 0.76 |
| WAN | 5 | 36000 | 0.66 | 0.75 | 0.77 | 0.78 |
| WAN | 15 | 12000 | 0.88 | 0.95 | 0.79 | 0.79 |
| WAN | 15 | 36000 | 0.96 | 0.96 | 0.86 | 0.89 |
| Column Average | 0.78 | 0.86 | 0.81 | 0.81 | ||
| Config- | Number of | Buffer | UBR | EPD | Selective | FBA |
| uration | Sources | Size (cells) | Drop | |||
| LAN | 5 | 1000 | 0.77 | 0.99 | 0.99 | 0.97 |
| LAN | 5 | 3000 | 0.93 | 0.99 | 1 | 0.99 |
| LAN | 15 | 1000 | 0.26 | 0.96 | 0.99 | 0.69 |
| LAN | 15 | 3000 | 0.87 | 0.99 | 0.99 | 1 |
| Column Average | 0.71 | 0.98 | 0.99 | 0.91 | ||
| WAN | 5 | 12000 | 0.99 | 1 | 0.99 | 1 |
| WAN | 5 | 36000 | 0.97 | 0.99 | 0.99 | 1 |
| WAN | 15 | 12000 | 0.91 | 0.96 | 0.99 | 0.95 |
| WAN | 15 | 36000 | 0.74 | 0.91 | 0.98 | 0.98 |
| Column Average | 0.90 | 0.97 | 0.99 | 0.98 | ||
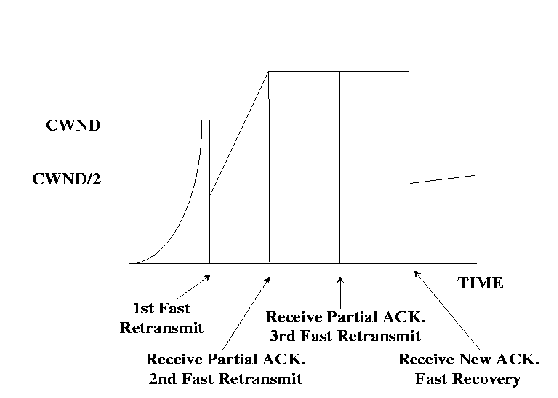
The ``fast-retransmit phase'' is introduced, in which the sender remembers the highest sequence number sent (RECOVER) when the fast retransmit is first triggered. After the first unacknowledged packet is retransmitted (when three duplicate ACKs are received), the sender follows the usual fast recovery algorithm and inflates the CWND by one for each duplicate ACK it receives. When the sender receives an acknowledgment for the retransmitted packet, it checks if the ACK acknowledges all segments including RECOVER. If so, the ACK is a new ACK, and the sender exits the fast retransmit-recovery phase, sets its CWND to SSTHRESH and starts a linear increase (congestion avoidance). If on the other hand, the ACK is a partial ACK, i.e., it acknowledges the retransmitted segment, and only a part of the segments before RECOVER, then the sender immediately retransmits the next expected segment as indicated by the ACK. This continues until all segments including RECOVER are acknowledged. This mechanism ensures that the sender will recover from N segment losses in N round trips.This is called ``New Reno.''
As a result, the sender can recover from multiple packet losses without having to time out. In case of small propagation delays, and coarse timer granularities, this mechanism can effectively improve TCP throughput over vanilla TCP. Figure 6shows the congestion window graph of a TCP connection for three contiguous segment losses. The TCP retransmits one segment every round trip time (shown by the CWND going down to 1 segment) until a new ACK is received.
In our implementation, we combined ``New Reno'' and SACK TCP as described in the following subsection.
TCP with Selective Acknowledgments (SACK TCP) has been proposed to efficiently recover from multiple segment losses [ 18]. In SACK TCP, acknowledgments contain additional information about the segments have been received by the destination. When the destination receives out-of-order segments, it sends duplicate ACKs (SACKs) acknowledging the out-of-order segments it has received. From these SACKs, the sending TCP can reconstruct information about the segments not received at the destination. When the sender receives three duplicate ACKs, it retransmits the first lost segment, and inflates its CWND by one for each duplicate ACK it receives. This behavior is the same as Reno TCP. However, when the sender, in response to duplicate ACKs, is allowed by the window to send a segment, it uses the SACK information to retransmit lost segments before sending new segments. As a result, the sender can recover from multiple dropped segments in about one round trip. Figure 7shows the congestion window graph of a SACK TCP recovering from segment losses. During the time when the congestion window is inflating (after fast retransmit has incurred), the TCP is sending missing packets before any new packets.
The SACK option is negotiated in the SYN segments during TCP connection establishment. The SACK information is sent with an ACK by the data receiver to the data sender to inform the sender of the out-of-sequence segments received. The format of the SACK packet has been proposed in [ 18]. The SACK option is sent whenever out of sequence data is received. All duplicate ACK's contain the SACK option. The option contains a list of some of the contiguous blocks of data already received by the receiver. Each data block is identified by the sequence number of the first byte in the block (the left edge of the block), and the sequence number of the byte immediately after the last byte of the block. Because of the limit on the maximum TCP header size, at most three SACK blocks can be specified in one SACK packet.
The receiver keeps track of all the out-of-sequence data blocks received. When the receiver generates a SACK, the first SACK block specifies the block of data formed by the most recently received data segment. This ensures that the receiver provides the most up to date information to the sender. After the first SACK block, the remaining blocks can be filled in any order.
The sender keeps a table of all the segments sent but not ACKed. When a segment is sent, it is entered into the table. When the sender receives an ACK with the SACK option, it marks all the segments specified in the SACK option blocks as SACKed. The entries for each segment remain in the table until the segment is ACKed. The remaining behavior of the sender is very similar to Reno implementations with the modification suggested in Section 5.3 4 . When the sender receives three duplicate ACKs, it retransmits the first unacknowledged packet. During the fast retransmit phase, when the sender is sending one segment for each duplicate ACK received, it first tries to retransmit the holes in the SACK blocks before sending any new segments. When the sender retransmits a segment, it marks the segment as retransmitted in the table. If a retransmitted segment is lost, the sender times out and performs slow start. When a timeout occurs, the sender resets the SACK table.
During the fast retransmit phase, the sender maintains a variable PIPE that indicates how many bytes are currently in the network pipe. When the third duplicate ACK is received, PIPE is set to the value of CWND and CWND is reduced by half. For every subsequent duplicate ACK received, PIPE is decremented by one segment because the ACK denotes a packet leaving the pipe. The sender sends data (new or retransmitted) only when PIPE is less than CWND. This implementation is equivalent to inflating the CWND by one segment for every duplicate ACK and sending segments if the number of unacknowledged bytes is less than the congestion window value.
When a segment is sent, PIPE is incremented by one. When a partial ACK is received, PIPE is decremented by two. The first decrement is because the partial ACK represents a retransmitted segment leaving the pipe. The second decrement is done because the original segment that was lost, and had not been accounted for, is now actually considered to be lost.
We now calculate a bound for the recovery behavior of SACK TCP, and show that SACK TCP can recover from multiple packet losses more efficiently than Reno or vanilla TCP. Suppose that at the instant when the sender learns of the first packet loss (from three duplicate ACKs), the value of the congestion window is CWND. Thus, the sender has CWND bytes of data waiting to be acknowledged. Suppose also that the network has dropped a block of data which is CWND/n bytes long (This will typically result in several segments being lost). After one RTT of sending the first dropped segment, the sender receives three duplicate ACKs for this segment. It retransmits the segment, and sets PIPE to CWND - 3, and sets CWND to CWND/2. For each duplicate ACK received, PIPE is decremented by 1. When PIPE reaches CWND, then for each subsequent duplicate ACK received, another segment can be sent. All the ACKs from the previous window take 1 RTT to return. For half RTT nothing is sent (since PIPE > CWND). For the next half RTT, if CWND/n bytes were dropped, then only CWND/2 - CWND/n bytes (of retransmitted or new segments) can be sent. In the second RTT, the sender can retransmit 2(CWND/2 - CWND/n) bytes. This is because for each retransmitted segment in the first RTT, the sender receives a partial ACK that indicates that the next segment is missing. As a result, PIPE is decremented by 2, and the sender can send 2 more segments (both of which could be retransmitted segments) for each partial ACK it receives.
Thus, the number of RTTs N
rec
needed by SACK TCP to recover from a loss of CWND/n is given by
If less than one fourth of CWND is lost, then SACK TCP can recover in 1 RTT. If more than one half the CWND is dropped, then there will not be enough duplicate ACKs for PIPE to become large enough to transmit any segments in the first RTT. Only the first dropped segment will be retransmitted on the receipt of the third duplicate ACK. In the second RTT, the ACK for the retransmitted packet will be received. This is a partial ACK and will result in PIPE being decremented by 2 so that 2 packets can be sent. As a result, PIPE will double every RTT, and SACK will recover no slower than slow start [ 2, 4]. SACK would still be advantageous because timeout would be still avoided unless a retransmitted packet were dropped.
We performed simulations for the LAN and WAN configurations for three drop policies - tail drop, Early Packet Discard and Selective Drop. Tables 6and 7show the efficiency and fairness values of SACK TCP with various UBR drop policies. Tables 8and 9show the comparative column averages for Vanilla, Reno and SACK TCP. Several observations can be made from these tables:
| Config- | Number of | Buffer | UBR | EPD | Selective |
| uration | Sources | (cells) | Drop | ||
| LAN | 5 | 1000 | 0.76 | 0.85 | 0.94 |
| LAN | 5 | 3000 | 0.98 | 0.97 | 0.98 |
| LAN | 15 | 1000 | 0.57 | 0.78 | 0.91 |
| LAN | 15 | 3000 | 0.86 | 0.94 | 0.97 |
| Column Average | 0.79 | 0.89 | 0.95 | ||
| WAN | 5 | 12000 | 0.90 | 0.88 | 0.95 |
| WAN | 5 | 36000 | 0.97 | 0.99 | 1.00 |
| WAN | 15 | 12000 | 0.93 | 0.80 | 0.88 |
| WAN | 15 | 36000 | 0.95 | 0.95 | 0.98 |
| Column Average | 0.94 | 0.91 | 0.95 | ||
| Config- | Number of | Buffer | UBR | EPD | Selective |
| uration | Sources | (cells) | Drop | ||
| LAN | 5 | 1000 | 0.22 | 0.88 | 0.98 |
| LAN | 5 | 3000 | 0.92 | 0.97 | 0.96 |
| LAN | 15 | 1000 | 0.29 | 0.63 | 0.95 |
| LAN | 15 | 3000 | 0.74 | 0.88 | 0.98 |
| Column Average | 0.54 | 0.84 | 0.97 | ||
| WAN | 5 | 12000 | 0.96 | 0.98 | 0.95 |
| WAN | 5 | 36000 | 1.00 | 0.94 | 0.99 |
| WAN | 15 | 12000 | 0.99 | 0.99 | 0.99 |
| WAN | 15 | 36000 | 0.98 | 0.98 | 0.96 |
| Column Average | 0.98 | 0.97 | 0.97 | ||
| Config- | UBR | EPD | Selective |
| uration | Drop | ||
| LAN | |||
| Vanilla TCP | 0.34 | 0.67 | 0.84 |
| Reno TCP | 0.69 | 0.97 | 0.97 |
| SACK TCP | 0.79 | 0.89 | 0.95 |
| WAN | |||
| Vanilla TCP | 0.91 | 0.9 | 0.91 |
| Reno TCP | 0.78 | 0.86 | 0.81 |
| SACK TCP | 0.94 | 0.91 | 0.95 |
| Config- | UBR | EPD | Selective |
| uration | Drop | ||
| LAN | |||
| Vanilla TCP | 0.69 | 0.69 | 0.92 |
| Reno TCP | 0.71 | 0.98 | 0.99 |
| SACK TCP | 0.54 | 0.84 | 0.97 |
| WAN | |||
| Vanilla TCP | 0.76 | 0.95 | 0.94 |
| Reno TCP | 0.90 | 0.97 | 0.99 |
| SACK TCP | 0.98 | 0.97 | 0.97 |
Even with a large number of TCP connections, EPD does not significantly affect fairness over vanilla UBR, because EPD does not perform selective discard of packets based on buffer usage. However, with a large number of sources, the fairness metric can take high values even in clearly unfair cases. This is because, as the number of sources increases, the effect of a single source or a few sources on the the fairness metric decreases. As a result, vanilla UBR might have a fairness value of 0.95 or better even if a few TCP's receive almost zero throughput. The effect of unfairness is easily seen with a small number of sources. Vanilla UBR and EPD are clearly unfair, and the performance of Selective Drop needs to be tested with large number of sources for a more strict value of fairness. [ 13] suggests that a value of 0.99 for the fairness metric reflects high fairness even for a large number of sources. Selective Drop should provide high efficiency and fairness in such cases.
We performed experiments with 50 and 100 TCP sources using SACK TCP and Selective Drop. The experiments were performed for WAN and satellite networks with the N source configuration. The simulations produced efficiency values of 0.98 and greater with fairness values of 0.99 and better for buffer sizes of 1 RTT and 3 RTT. The simulations produced high efficiency and fairness for fixed buffer sizes, irrespective of the number of sources (5, 15, 50 or 100). The details of the simulation results with a large number sources have been published as part of a separate study in [ 15]. The simulation results illustrate that SACK TCP with a per-VC buffer management policy like Selective Drop can produce high efficiency and fairness even for a large number of TCP sources.
From the simulation and analysis presented in this paper, we know that vanilla TCP performs poorly because TCP sources waste bandwidth when they are waiting for a timeout. Reno TCP performs poorly in the case of multiple packet losses because of timeout, and congestion avoidance at a very low window size. The effect of these behaviors is mitigated with a large number of sources. When a large number of sources are fairly sharing the link capacity, each TCP gets a small fraction of the capacity, and the steady state window sizes of the TCPs are small. When packets are lost from a few TCPs, other TCPs increase their congestion widows to utilize the unused capacity within a few round trips. As a result, overall link efficiency improves, but at the expense of the TCPs suffering loss. The TCPs that lose packets recover the fastest with SACK TCP. Thus, SACK TCP can help in quickly achieving fairness after packet loss.
To conclude, TCP performance over UBR can be improved by either improving TCP using selective acknowledgments, or by introducing intelligent buffer management policies at the switches. Efficient buffer management has a more significant influence on LANs because of the limited buffer sizes in LAN switches compared to the TCP maximum window size. In WANs, the drop policies have a smaller impact because both the switch buffer sizes and the TCP windows are of the order of the bandwidth-delay product of the network. Also, the TCP linear increase is much slower in WANs than in LANs because the WAN RTTs are higher.
In this paper we have not presented a comprehensive comparative study of TCP performance with other per-VC buffer management schemes. This is a topic of further study, and is beyond the scope of this paper. Also, the present version of Selective Drop assigns equal weight to the competing connections. Selective Drop with weighted fairness is a topic of further study.