 |
Rohit Goyal, Raj Jain, Sonia Fahmy, and Bobby Vandalore
The Ohio State University Department of Computer and Information Science
Columbus, OH 43210-1277
Contact author E-mail: jain@acm.org
Abstract:
Keywords:ATM, UBR, GFR, Buffer Management, TCP
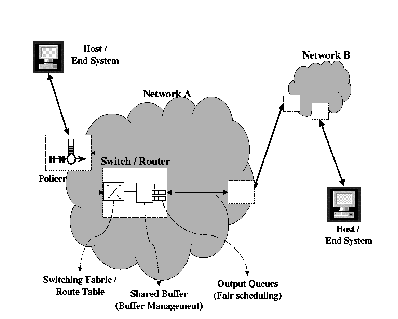
The original GFR proposals [ 11, 12] give the basic definition of the GFR service. GFR provides a minimum rate guarantee to the framesof a VC. The guarantee requires the specification of a maximum frame size (MFS) of the VC. If the user sends packets (or frames) smaller than the maximum frame size, at a rate less than the minimum cell rate (MCR), then all the packets are expected to be delivered by the network with minimum loss. If the user sends packets at a rate higher than the MCR, it should still receive at least the minimum rate. The minimum rate is guaranteed to the untagged frames of the connection. In addition, a connection sending in excess of the minimum rate should receive a fair share of any unused network capacity. The exact specification of the fair share has been left unspecified by the ATM Forum. Although the GFR specification is not yet finalized, the above discussion captures the essence of the service.
There are three basic design options that can be used by the networkto provide the per-VC minimum rate guarantees for GFR - tagging, buffer management, and queueing:
Several proposals have been made [ 3, 4, 8] to provide rate guarantees to TCP sources with FIFO queuing in the network. The bursty nature of TCP traffic makes it difficult to provide per-VC rate guarantees using FIFO queuing. Per-VC scheduling was recommended to provide rate guarantees to TCP connections. However, all these studies were performed at high target network utilization, i.e., most of the network buffers were allocated to the GFR VCs. We show that rate guarantees are achievable with a FIFO buffer for low buffer allocation.
All the previous studies have examined TCP traffic with a single TCP per VC. Per-VC buffer management for such cases reduces to per-TCP buffer management. However, routers that would use GFR VCs, would multiplex many TCP connections over a single VC. For VCs with several aggregated TCPs, per-VC control is unaware of each TCP in the VC. Moreover, aggregate TCP traffic characteristics and control requirements may be different from those of single TCP streams.
In this paper, we study two main issues:
Section 2discusses the behavior of TCP traffic with controlled windows. This provides insight into controlling TCP rates by controlling TCP windows. Section 3describes the effect of buffer occupancy and thresholds on TCP throughput. Section 4presents a simple threshold-based buffer management policy to provide TCP throughputs in proportion to buffer thresholds for low rate allocations. This scheme assumes that each GFR VC may carry multiple TCP connections. We then present simulation results with TCP traffic over LANs interconnected by an ATM network. In our simulation and analysis, we use SACK TCP [ 10] as the TCP model.
However, a window limit is not enforceable by the network to control the TCP rate. TCP sources respond to packet loss by reducing the source congestion window by one-half, and then increasing it by one segment size every round trip. As a result, the average TCP window can be controlled by packet discard at specific CWND values.
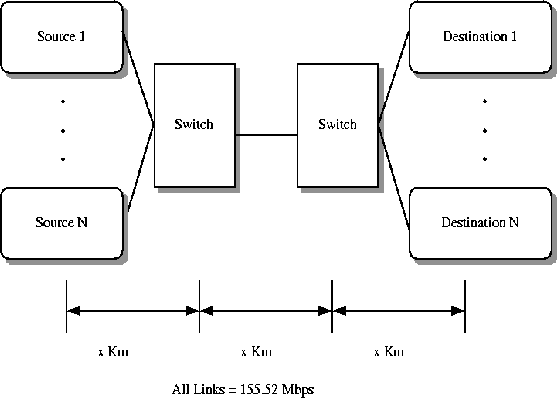
Figure 3shows how the source TCP congestion window varies when a single segment is lost at a particular value of the congestion window. The figure is the CWND plot of the simulation of the configuration shown in Figure 4with a single SACK TCP source (N=1). The figure shows four different values of the window at which a packet is lost. The round trip latency (RTT) for the connection is 30 ms. The window scale factor is used to allow the TCP window to increase beyond the 64K limit.
For window based flow control, the throughput (in Mbps) can be calculated from the average congestion window (in Bytes) and the round trip time (in seconds) as:
From Figure 3, the average congestion windows in the linear phases of the four experiments are approximately 91232 bytes, 181952 bytes, 363392 bytes and over 600000 bytes. As a result, the average calculated throughputs from equation 1are 24.32 Mbps, 48.5 Mbps, 96.9 Mbps, and 125.6 Mbps (126 Mbps is the maximum possible TCP throughput for a 155.52 Mbps link with 1024 byte TCP segments). The respective throughputs obtained from the simulations of the four cases are 23.64 Mbps, 47.53 Mbps, 93.77 Mbps and 25.5 Mbps. The throughput values calculated from the average congestion windows are close to those obtained by simulation. This shows that controlling the TCP window so as to maintain a desired average window size enables the network to control the average TCP throughput.
|
In a FIFO buffer, the output rate of a connection is determined by the number of packets of the connection in the buffer. Let
![]() and x
i
be the output rate and the buffer occupancy respectively of VC
i
. Let
and x
i
be the output rate and the buffer occupancy respectively of VC
i
. Let
![]() and xbe the total output rate and the buffer occupancy of the FIFO buffer respectively. Then, by the FIFO principle, in steady state,
and xbe the total output rate and the buffer occupancy of the FIFO buffer respectively. Then, by the FIFO principle, in steady state,
Adaptive flows like TCP respond to segment loss by reducing their congestion window. A single packet loss is sufficient to reduce the TCP congestion window by one-half. Consider a drop policy that drops a single TCP packet from a connection every time the connection's buffer occupancy crosses a given threshold. The drop threshold for a connection determines the maximum size to which the congestion window is allowed to grow. Because of TCP's adaptive nature, the buffer occupancy reduces after about 1 RTT. The drop policy drops a single packet when the TCP's buffer occupancy crosses the threshold, and then allows the buffer occupancy to grow by accepting the remainder of the TCP window. On detecting a loss, TCP reduces its congestion window by 1 segment and remains idle for about one-half RTT, during which the buffer occupancy decreases below the threshold. Then the TCP window increases linearly (and so does the buffer occupancy), and a packet is again dropped when the buffer occupancy crosses the threshold. In this way, TCP windows can be controlled quite accurately to within one round trip time. As a result, the TCP's throughput can also be controlled by controlling the TCP's buffer occupancy.
| Experiment number | 1 | 2 | 3 | 4 |
| TCP number | Threshold per TCP (cells) (r i ) | |||
| 1-3 | 305 | 458 | 611 | 764 |
| 4-6 | 611 | 917 | 1223 | 1528 |
| 7-9 | 917 | 1375 | 1834 | 2293 |
| 10-12 | 1223 | 1834 | 2446 | 3057 |
| 13-15 | 1528 | 2293 | 3057 | 3822 |
| Total threshold (r) | 13752 | 20631 | 27513 | 34392 |
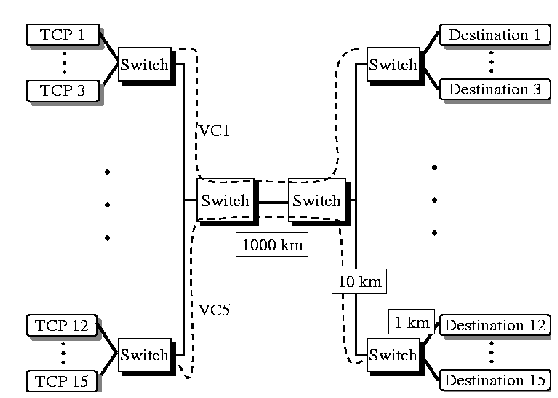
Using this drop policy, we performed simulations of the TCP configuration in Figure
4with fifteen TCP sources divided into 5 groups of 3 each. Each TCP source was a separate UBR VC. Five different buffer thresholds (r
i
) were selected, and each of three TCP's in a group had the same buffer threshold. Table
1lists the buffer thresholds for the VC's in the FIFO buffer of the switches. We performed experiments with 4 different sets of thresholds as shown by the threshold columns. The last row in the table shows the total buffer allocated (
![]() ) to all the TCP connections for each simulation experiment. The total buffer size was large (48000 cells) so that there was enough space for the buffers to increase after the single packet drop. For a buffer size of 48000 cells, the total target buffer utilizations were 29%, 43%, 57%, 71% in the 4 columns of table
1respectively. The selected buffer thresholds determine the MCR achieved by each connection. For each connection, the ratios of the thresholds to the total buffer allocation should be proportional to the ratios of the achieved per-VC throughputs to the total achieved throughput. In other words, if
) to all the TCP connections for each simulation experiment. The total buffer size was large (48000 cells) so that there was enough space for the buffers to increase after the single packet drop. For a buffer size of 48000 cells, the total target buffer utilizations were 29%, 43%, 57%, 71% in the 4 columns of table
1respectively. The selected buffer thresholds determine the MCR achieved by each connection. For each connection, the ratios of the thresholds to the total buffer allocation should be proportional to the ratios of the achieved per-VC throughputs to the total achieved throughput. In other words, if
![]() ,
,
![]() , r
i
and rrepresent the per-VC achieved throughputs, total throughput, per-VC buffer allocations, and total buffer allocation respectively, then we should have
, r
i
and rrepresent the per-VC achieved throughputs, total throughput, per-VC buffer allocations, and total buffer allocation respectively, then we should have
| Experiment number | 1 | 2 | 3 | 4 | |
| TCP number | Achieved throughput per TCP (Mbps) (
|
Expected Throughput | |||
| (
| |||||
| 1-3 | 2.78 | 2.83 | 2.95 | 3.06 | 2.8 |
| 4-6 | 5.45 | 5.52 | 5.75 | 5.74 | 5.6 |
| 7-9 | 8.21 | 8.22 | 8.48 | 8.68 | 8.4 |
| 10-12 | 10.95 | 10.89 | 10.98 | 9.69 | 11.2 |
| 13-15 | 14.34 | 13.51 | 13.51 | 13.93 | 14.0 |
| Total throughput (
|
125.21 | 122.97 | 125.04 | 123.35 | 126.0 |
Table 2shows the average throughput obtained per TCP in each group for each of the four simulations. The TCP throughputs were averaged over each group to reduce the effects of randomness. The last row of the table shows the total throughput obtained in each simulation. Based on the TCP segment size (1024 bytes) and the ATM overhead, it is clear that the TCPs were able to use almost the entire available link capacity (approximately 126 Mbps at the TCP layer).
| Experiment number | 1 | 2 | 3 | 4 | |
| TCP number | Ratio (
|
||||
| 1-3 | 1.00 | 1.03 | 1.02 | 1.08 | |
| 4-6 | 0.98 | 1.01 | 1.03 | 1.04 | |
| 7-9 | 0.98 | 1.00 | 1.00 | 1.02 | |
| 10-12 | 0.98 | 0.99 | 0.98 | 0.88 | |
| 13-15 | 1.02 | 0.98 | 0.97 | 1.01 | |
The proportion of the buffer usable by each TCP (r
i
/r) before the single packet drop should determine the proportion of the throughput achieved by the TCP. Table
3shows the ratios
![]() for each simulation. All ratios are close to 1. This indicates that the TCP throughputs are indeed proportional to the buffer allocations. The variations (not shown in the table) from the mean TCP throughputs increased as the total buffer thresholds increased (from left to right across the table). This is because the TCPs suffered a higher packet loss due to the reduced room to grow beyond the threshold. Thus, high buffer utilization produced more variation in achieved rate (last column of Table
3), whereas in low utilization cases, the resulting throughputs were in proportion to the buffer allocations.
for each simulation. All ratios are close to 1. This indicates that the TCP throughputs are indeed proportional to the buffer allocations. The variations (not shown in the table) from the mean TCP throughputs increased as the total buffer thresholds increased (from left to right across the table). This is because the TCPs suffered a higher packet loss due to the reduced room to grow beyond the threshold. Thus, high buffer utilization produced more variation in achieved rate (last column of Table
3), whereas in low utilization cases, the resulting throughputs were in proportion to the buffer allocations.
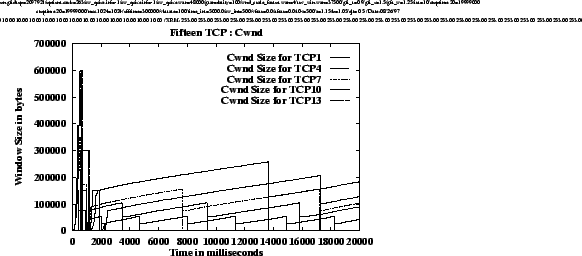
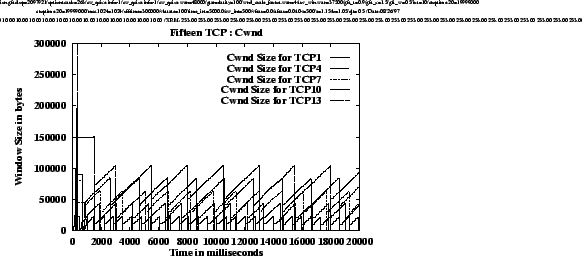
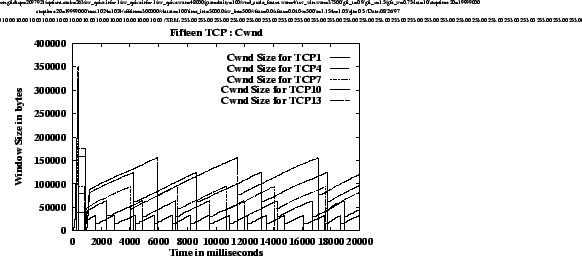
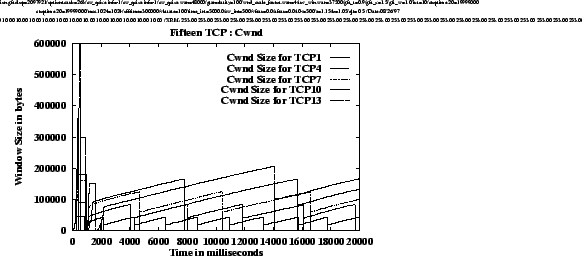
Figure
5shows the congestion windows of one TCP from each group for each of the four simulations. The graphs illustrate that the behaviors of the TCP congestion windows are very regular in these cases. The average throughput achieved by each TCP can be calculated from the graphs using equations
1and
2. An intersting observation is that for each simulation, the slopes of the graphs during the linear increase are approximately the same for each TCP, i.e., for a given simulation, the rate of increase of CWND is the same for all TCPs regardless of their drop thresholds. We know that TCP windows increase by 1 segment every round trip time. Thus, we can conclude that for a given simulation, TCPs sharing the FIFO buffer experience similar queuing delays regardless of the individual per-connection thresholds at which their packets are dropped. This is because, if all TCP's buffer occupancies are close to their respective thresholds (r
i
), then when a packet arrives at the buffer, it is queued behind cells from
![]() packets, regardless of the connection to which it belongs. Consequently, each TCP experiences the same average queuing delay.
packets, regardless of the connection to which it belongs. Consequently, each TCP experiences the same average queuing delay.
However, as the total buffer threshold increases (from experiment (a) to (d)), the round trip time for each TCP increases because of the larger total queue size. The larger threshold also results in a larger congestion window at which a packet is dropped. A larger congestion window means that TCP can send more segments in one round trip time. But, the round trip time also increases proportionally to the increase in CWND (due to the increasing queuing delay of the 15 TCPs bottlenecked at the first switch). As a result, the average throughput achieved by a single TCP remains almost the same (see table 2) across the simulations. The formal proof of these conclusions will be presented in an extended version of this paper.
The following list summarizes the observations from the graphs:
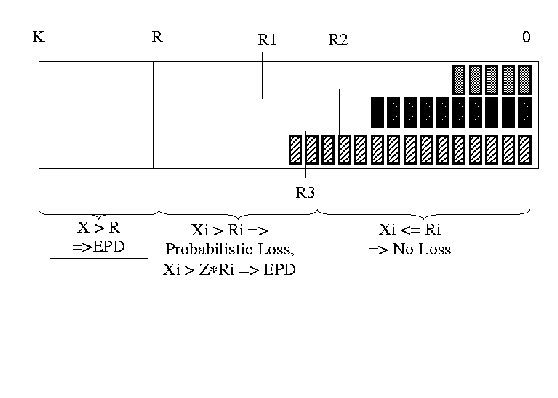
Figure 6illustrates a FIFO buffer for the GFR service category. The following attributes are defined:
When the first cell of a frame arrives at the buffer, if the number of cells (X
i
) of VC
i
in the buffer is less than its threshold (R
i
) and if the total buffer occupancy Xis less than R, then the cell and frame is accepted into the buffer. If X
i
is greater than R
i
, and if the total buffer occupancy (X) is greater than the buffer threshold (R), or if X
i
is greater than
![]() , then the cell and frame are dropped (EPD). Thus Zspecifies a maximum per-VC buffer occupancy during congestion periods. Under low or mild load conditions,
, then the cell and frame are dropped (EPD). Thus Zspecifies a maximum per-VC buffer occupancy during congestion periods. Under low or mild load conditions,
![]() should be large enough to buffer a burst of cells without having to perform EPD. If the X
i
is greater than R
i
, and Xis less than R, then the cell/frame are dropped in a probabilistic manner. The probability of frame drop depends on how much X
i
is above R
i
, as well as the weight (W
i
) of the connection. As X
i
increases beyond R
i
, the probability of drop increases. Also, the drop probability should be higher for connections with a higher threshold. This is because, TCP flows with higher windows (due to higher thresholds) are more robust to packet loss than TCP flows with lower windows. Moreover, in the case of merged TCPs over a single VC, VCs with a high threshold are likely to carry more active TCP flows than those with a low threshold. As a result, a higher drop probability is more likely to hit more TCP sources and improve the fairness within a VC. W
i
is used to scale the drop probability according to desired level of control.
should be large enough to buffer a burst of cells without having to perform EPD. If the X
i
is greater than R
i
, and Xis less than R, then the cell/frame are dropped in a probabilistic manner. The probability of frame drop depends on how much X
i
is above R
i
, as well as the weight (W
i
) of the connection. As X
i
increases beyond R
i
, the probability of drop increases. Also, the drop probability should be higher for connections with a higher threshold. This is because, TCP flows with higher windows (due to higher thresholds) are more robust to packet loss than TCP flows with lower windows. Moreover, in the case of merged TCPs over a single VC, VCs with a high threshold are likely to carry more active TCP flows than those with a low threshold. As a result, a higher drop probability is more likely to hit more TCP sources and improve the fairness within a VC. W
i
is used to scale the drop probability according to desired level of control.
The frame is dropped with a probability
In addition, if X i is greater than R i , then all tagged frames may also be dropped. Tagging support is not yet tested for this drop policy.
The resulting algorithm works as follows. When the first cell of a frame arrives:
IF ((Xi < Ri AND X < R)) THEN ACCEPT CELL AND REMAINING CELLS IN FRAME ELSE IF ((X < R) AND (Xi < Z*Ri) AND (Cell NOT Tagged) AND (u > Wi*(Xi - Ri)/(Ri(Z-1)))) THEN ACCEPT CELL AND REMAINING CELLS IN FRAME ELSE DROP CELL AND REMAINING CELLS IN FRAME ENDIF
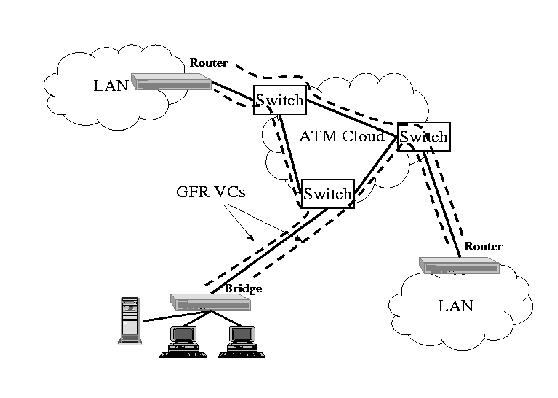
Figure 7illustrates the 15 TCP configuration in which groups of three TCPs are merged into 1 single VC. Each local switch (edge device separating the LAN from the backbone ATM network) merges the 3 TCPs into a single GFR VC over the backbone link. The backbone link has 5 VCs going through it, each with 3 TCPs. The local switches ensure that the cells of frames within a single VC are not interleaved. The backbone switches implement the buffer allocation policy described above. The local switches are not congested in this configuration.
We simulated the 15 merged TCP configuration with 3 different buffer threshold sets. The parameter Zwas set to 1.5, therefore, EPD was performed for each VC when its buffer occupancy was
![]() . Table
4shows the thresholds used for each VC at the first bottleneck switch.
. Table
4shows the thresholds used for each VC at the first bottleneck switch.
Table
5shows the ratio
![]() for each VC for the configuration in Figure
7and the corresponding thresholds. In all cases, the achieved link utilization was almost 100%. The table shows that TCP throughputs obtained were in proportion to the buffers allocated (since most of the ratios in table
5are close to 1). The highest variation (not shown in the table) was seen in the last column because of the high threshold values.
for each VC for the configuration in Figure
7and the corresponding thresholds. In all cases, the achieved link utilization was almost 100%. The table shows that TCP throughputs obtained were in proportion to the buffers allocated (since most of the ratios in table
5are close to 1). The highest variation (not shown in the table) was seen in the last column because of the high threshold values.
| VC number | Threshold (cells) | ||
| 1 | 152 | 305 | 611 |
| 2 | 305 | 611 | 1223 |
| 3 | 458 | 917 | 1834 |
| 4 | 611 | 1223 | 2446 |
| 5 | 764 | 1528 | 3057 |
| Total | 2290 | 4584 | 9171 |
| VC number | Ratio
| ||
| 1 | 1.04 | 1.01 | 1.16 |
| 2 | 1.05 | 1.02 | 1.06 |
| 3 | 0.97 | 0.99 | 1.05 |
| 4 | 0.93 | 1.00 | 1.13 |
| 5 | 1.03 | 0.99 | 0.80 |
In our simulations, the maximum observed queue sizes in cells in the first backbone switch (the main bottleneck) were 3185, 5980 and 11992 respectively. The total allocated buffer thresholds were 2230, 4584 and 9171 cells for the experiments. At higher buffer allocations, the drop policy cannot provide tight bounds on throughput.
More work remains to be done to further modify the buffer management scheme to work with a variety of configurations. In particular, we have only studied the performance of this scheme with SACK TCP. Its performance with heterogeneous TCPs is a topic of further study. We have not studied the effect of non adaptive traffic (like UDP) on the drop policy. It appears that for non adaptive traffic, the thresholds must be set lower than those for adaptive traffic (for the same MCR), and the dropping should be more strict when the buffer occupancy crosses the threshold. In this paper we have not studied the effect of network based tagging in the context of GFR. In the strict sense, GFR only provides a low CLR guarantee to the CLP=0 cell stream i.e., the cells that were not tagged by the source and passed the GCRA conformance test. However, when source (this could be a non-ATM network element like a router) based tagging is not performed, it is not clear if the CLP0 stream has any significance over the CLP1 stream. Moreover, network tagging is an option that must be signaled during connection establishment.
![\includegraphics[height=3.2in,angle=-90]{figs/cwnd1a}](img9.gif) []
[]
![\includegraphics[height=3.2in,angle=-90]{figs/cwnd1b}](img10.gif)
![\includegraphics[height=3.2in,angle=-90]{figs/cwnd1c}](img11.gif) []
[]
![\includegraphics[height=3.2in,angle=-90]{figs/cwnd1d}](img12.gif)
 []
[]
 []
[]