| Michael Scholl, mss4@wustl.edu (A paper written under the guidance of Prof. Raj Jain) |
Download |
High availability is one of the major goals of smart grid systems. This paper examines the availability of wind turbines, a high voltage DC (HVDC) transmission system, and a supervisory control and data acquisition (SCADA)/outage management system (OMS)/distribution management system (DMS) control system as examples of electricity generation, transmission, and control systems in a smart grid. It also examines the sensitivity of each system to improvements in component availability in order to determine where to focus availability improvements. The results show that improvements in supplier software on the front end protocol (FEP) of the control system and better backup sites for the control system provide the largest increases in the availability of the entire system.
Keywords: Smart Grid, Performance Analysis, Availability, Sensitivity Analysis
As technological advances are made there has been a push to update the electrical grid to take advantage of new technologies. Such a technologically advanced electrical grid is often called a "smart grid" and is often more efficient, more secure, and more reliable. These smart grids, however, have more components, all of which are capable of breaking down and causing the grid to go dark. One of the ways to analyze how often this happens is to look at the availability of the system.
The electrical grid is often considered to have four distinct operations: electricity generation, electric power transmission, electricity distribution, and electricity control. There have been studies on the availability of smart grid generation [Ribrant07], transmission [Zadkhast10], and control [Jensen10], but there has not been a study on the sensitivity of the systems to improvements in the availability of different components. This paper examines the data collected in these previous studies in order to determine which components to focus on in order to improve the overall availability of the smart grid.
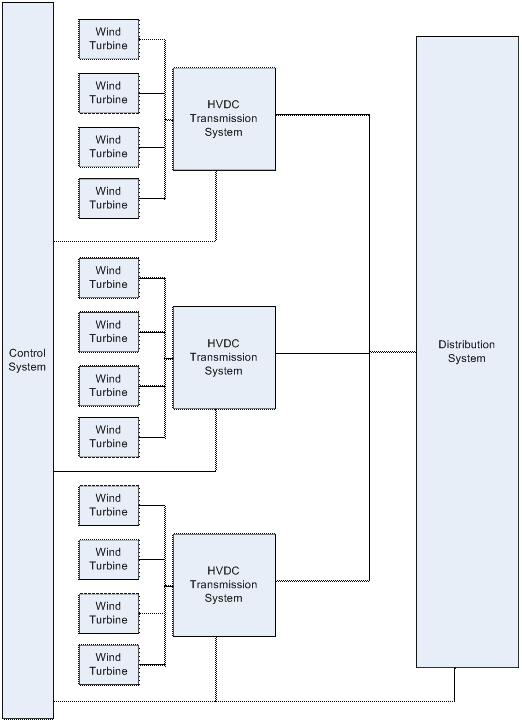
The grid examined in this paper is based on Figure 1. This model uses wind turbines as the generators, High Voltage DC (HVDC) transmission systems for power transmission, and a supervisory control and data acquisition (SCADA)/outage management system (OMS)/distribution management system (DMS) control system. The supplier software on the front end protocol (FEP) of the control system and better backup sites for the control system are shown to have the largest improvements on the availability of the smart grid.
Availability is important because it provides a metric for identifying the likelihood that a system is operational. This is done by comparing how long it takes a component to break down to how long it takes to fix the component. If the time it takes a component to break is considered to be an exponentially distributed function it can be expressed as:
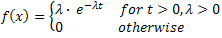
In this case the average time for a component to fail is called the mean time to failure (MTTF) and is equal to 1/labmda. Similarly, the time it takes to fix a component can be modeled as an exponentially distributed function with the parameter �. The average time it takes to fix a component is called the mean time to repair (MTTR) and is equal to 1/�. The availability of the system, therefore, is defined as:
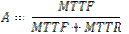
For a system with components in series the overall availability is simply the product of each component‘s availability:
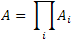
Most systems, however, consist of a series of systems, each of which has ki redundant components that are in parallel. The overall availability of such a system is 1 minus the product of 1 minus the availability raised to k for each subsystem [Rausand04]:
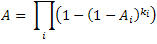
One of the benefits of having an intelligent electrical grid is the ability to incorporate renewable energy sources, such as wind power, which do not produce a constant amount of power. Wind power is harnessed by wind turbines which spin when the wind blows, turning a shaft connected to a generator, which converts the mechanical energy to electrical energy.
For the purposes of collecting failure information, wind turbines were split into 12 parts as shown in Figure 2: the electrical system, sensors, the blades and pitch system, hydraulic systems, the control system, the gearbox, the yaw system, the generator, the structure, mechanical brakes, the main shaft and bearings (drive train), and the hub [Besnard10]. A 13th category, the entire system, was added to account for other failures. If any of these systems fails then the whole turbine is considered to have failed.
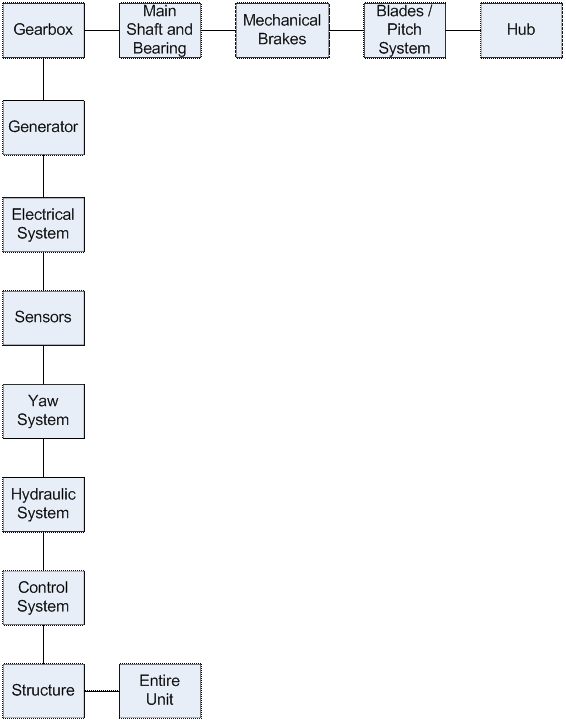
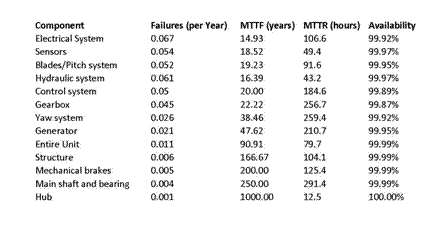
The data collected in [Ribrant07] is compiled in Table 1. Because the parts are connected in series, the overall availability is the product of the individual component availabilities. This comes out to 99.40%.
In order to determine which component improves the overall availability the most, a sensitivity analysis is performed. This is done by looking at how the availability of the overall system changes when one component‘s availability is changed to 100%. For the wind turbine this analysis produces the results in Table 2.
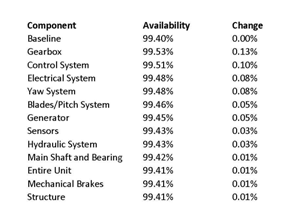
From this data it is shown that improving the availability of the gearbox has the largest effect on the availability of the wind turbine as a whole. This is expected because the wind turbine is a collection of components connected in series, so improving the worst component provides the largest overall improvement.
Electricity is generally generated and consumed as alternating current. When transmitting a lot of power over a long distance, however, it is often better to use direct current. In order to do this, the energy is converted from AC to DC at the sending end of a HVDC system and converted from DC back into AC at the receiving end. As smart grids start to shift to more distributed power generation, adding more than one terminal to either end becomes increasingly beneficial. In addition, it may be cost-effective to use a tapping station to get energy from small generators or provide energy to areas with small demands. This can be done effectively through the use of a voltage-sourced converter (VSC).
As shown in Figure 3, the sending and receiving ends of a HVDC transmission system both consist of the same four subsystems connected in series. The first subsystem consists of capacitors and AC filters in parallel. The second subsystem is the collection of poles, each of which has a breaker, a transformer, valves, and a smoothing reactor in series. In this model there are two poles at both the sending and receiving end. The third subsystem is a set of DC filters connected in parallel. Finally there is a pair of DC transmission lines connected in parallel. The VSC tapping station is modeled as a DC switch, a DC filter, valves, a transformer, a breaker, an AC filter, and capacitors connected in series. It is connected by the DC switch to the DC transmission lines.
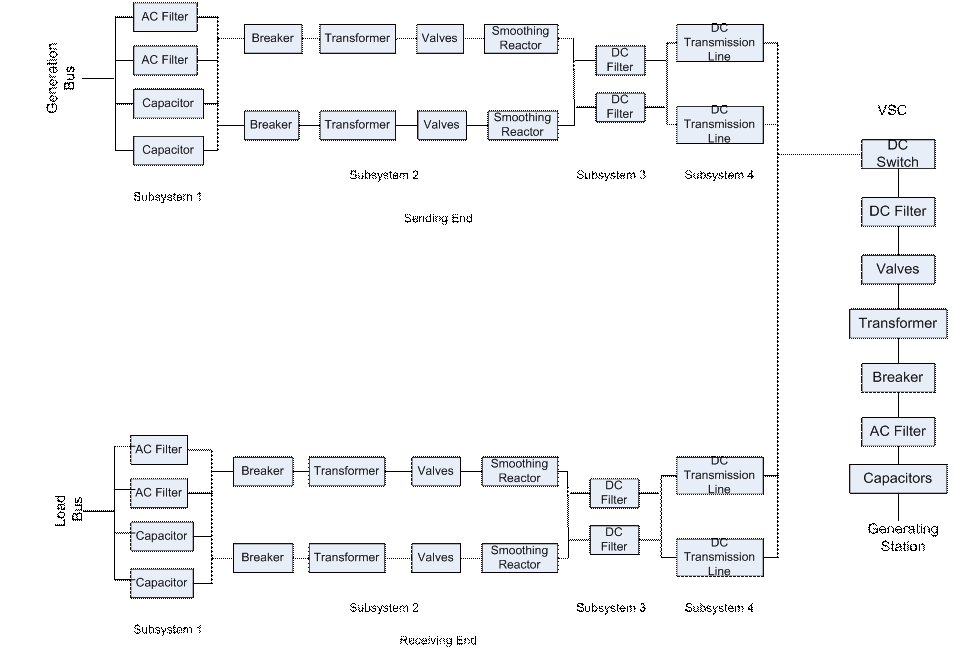
Because many of the parts of HVDC transmission system are in parallel, it is possible for the system to still operate, at a diminished capacity, even if one part fails. For the purpose of this analysis the system is considered unavailable only if its capacity is 0. Also, the entire system is considered unavailable if either end or the tapping station is unavailable. The data collected in [Zadkhast10] is compiled in Table 3 and the availability of each component is computed.
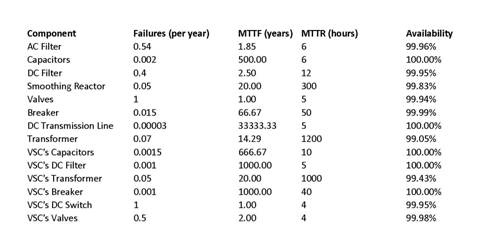
Using the availability of the components the availability of each subsystem and the system as a whole has been calculated in Table 4.
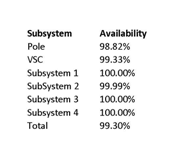
Once again a sensitivity analysis is performed on the system to see which component has the largest effect on the overall system, with the results shown in Table 5.
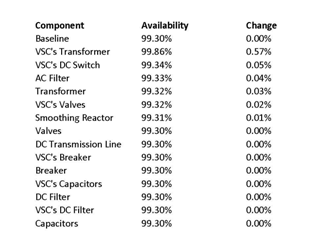
This analysis shows that the VSC‘s transformer has the largest effect by a clear margin. This makes sense because the transformer and VSC‘s transformer have the worst availability, but the transformer is part of a parallel system, so even if it fails it is possible for the system to be available, meaning it has a smaller effect.
Another aspect of a smart grid is the ability to respond quickly to new conditions. In order to do this it needs to have an intelligent control system. New control systems employ a supervisory control and data acquisition (SCADA) system, an outage management system (OMS), and a distribution management system (DMS) in order to collect information about the grid and react to problems.
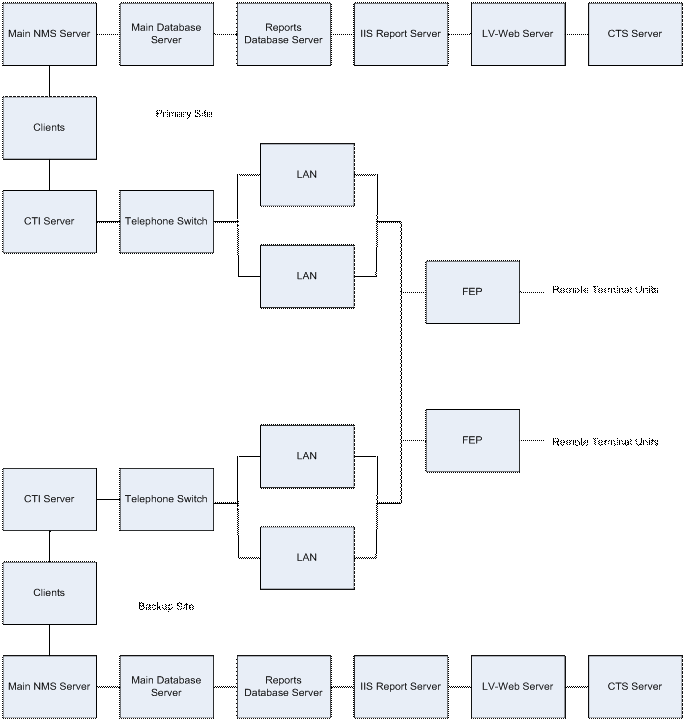
The control system can be divided into many parts as shown in Figure 4. There is a network management system (NMS) server, a main database server, and a reports database server, all of which have hardware, software, and data components. In addition, the NMS server has a special case called data stick which occurs frequently enough to consider separately. There is also an internet information services (IIS) report server, a LabView (LV)-web server, a CTS server, clients, and a computer telephony integration (CTI) server all of which have hardware and software components. In addition there are front end protocols (FEPs) which are split into DDN hardware, NFE hardware, FEP hardware, DDN software, NFE software, international electrotechnical commission (IEC)-104 software, inter-control center communications protocol (ICCP) software, and FEP software components, a telephone switch, and local area networks (LANs).
Instead of having a MTTF, [Jensen10] provides information on the number of failures over different time periods. Because the MTTF is exponentially distributed the MTTF can be calculated by dividing the observed time by the number of failures. If no failures were observed then the MTTF is said to be 8 and the availability is 100%. The data from [Jensen10] and the calculated availability are compiled in Table 6.
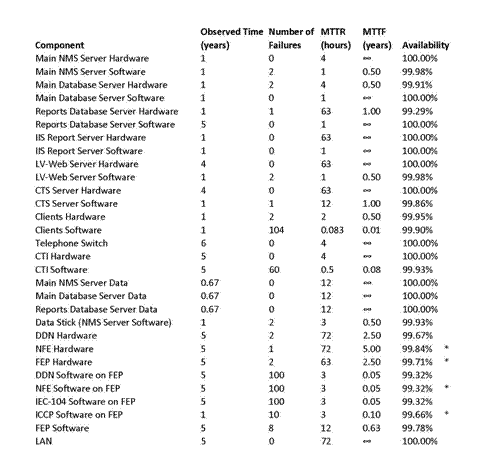
The asterisks indicate data that differs from the original calculations in [Jensen10]. These differences are mostly insignificant, but the difference for ICCP software on the FEP affects the sensitivity analysis results.
We can condense this data into a number of subsystems, including the CTI server, the NMS server, the clients, LAN A and B, the IIS report server, the LV-web server, the CTS server, the main database server, the reports database server, the telephone switch, and the FEP. The overall system has one primary site, one backup site, and two FEPs. As [Jensen10] points out, the backup only has 15% of the clients the primary site has, but 20% are needed to handle normal outage situations, so the backup site is never considered available. The availability of each subsystem is shown in Table 7.

When looking at the sensitivity analysis of the control system in Table 8 it quickly becomes clear that the supplier FEP software and the lack of clients at the backup site have large effects on the overall system availability.
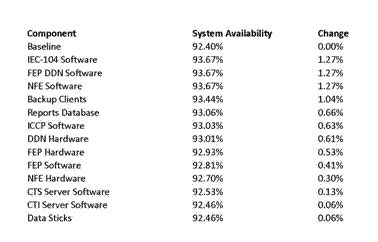
The analysis in this paper shows that both wind turbines and HVDC transmission systems have high availability. For wind turbines there is not much that can be done to improve the availability. For the HVDC transmission systems improving the transformers of the tapping station‘s VSC can improve the availability by a noticeable amount. The big improvement in availability, however, is going to come from the control system. Fixing the supplier software on the FEP or adding more clients to the backup site(s) cause the availability to improve by a full percent. In addition, a grid, like the model in Figure 1, would have many turbines and several HVDC transmission lines in parallel, but only one control system, making it the most vulnerable point.
[1] Johan Ribrant, Lina Margareta Bertling, "Survey of Failures in Wind Power Systems With Focus on Swedish Wind Power Plants During 1997-2005", IEEE Transactions on Energy Conversion, March 2007, 167-173, http://ieeexplore.ieee.org/document/4106014/
A collection of failure data from wind turbines in Sweden.
[2] Sajjad Zadkhast, Mahmud Fotuhi-Firuzabad, Farrokh Aminifar, Roy Billinton, Sherif Omar Faried, Abdel-Aty Edris, "Reliability Evaluation of an HVDC Transmission System Tapped by a VSC Station", IEEE Transactions on Power Delivery, July 2010, 1962-1970, http://ieeexplore.ieee.org/document/5446297/
An examination of the reliability of a multi-terminal transmission system with a tapping station.
[3] Mark Jensen, Cumhur Sel, Ulrik Franke, Hannes Holm, Lars Nordstrom, "Availability of a SCADA/OMS/DMS System − a Case Study", 2010 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT Europe), 2010, http://ieeexplore.ieee.org/document/5638912/
An in-depth look at the availability and sensitivity of a SCADA/OMS/DMS control system.
[4] M. Rausand, A. Hoyland, System Reliability Theory: Models, Statistical Methods and Applications, 2nd ed. Wiley, 2004, [Online]. http://www.ntnu.no/ross/srt/
A good introduction to reliability theory including availability.
[5] Francois Besnard, Katharina Fischer, Lina Bertling, "Reliability-Centred Asset Maintenance − A step towards enhanced reliability, availability, and profitability of wind power plants", 2010 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT Europe), 2010, http://www.ieeexplore.ieee.org/document/5638986/
A look at a new maintenance algorithm that includes a brief overview of the data from [1].
CTI − Computer Telephony Integration
DMS − Distribution Management System
FEP − Front End Protocol
HVDC − High Voltage Direct Current
ICCP − Inter-Control Center Communications Protocol
IEC − International Electrotechnical Commission
IIS − Internet Information Services
LV − LabView
MTTF − Mean Time To Failure
MTTR − Mean Time To Repair
NMS − Network Management Services
OMS − Outage Management System
RTU − Remote Terminal Unit
SCADA − Supervisory Control And Data Acquisition
VSC − Voltage-Source Converter